1. 정보 이론(Information Theory)에서 말하는 ‘정보’
응용 수학 학문의 갈래에는 수없이 많은 해괴한 이론들이 도사리고 있습니다. 정보 이론(Information Theory)는 그 중에서도 공대생들에게 상당히 귀에 낯익는 용어임에도, 여기서 말하는 ‘정보’라는게 일상적으로 쓰는 그 개념 그 자체인지 항상 모호할 때가 있었습니다.
위키를 비롯한 여러 자료들에서는 정보 이론을 다음과 같이 요약하고 있습니다.
정보, 데이터의 가치를 수학적으로 정량화하는 이론
일상대화에 사용되는 “이건 유익한 정보다”, 또는 “별로 의미없는 정보였네”와 같은 표현처럼, 정보나 특정 사건, 관측치의 중요도를 수치화하여 나타내는 접근법으로 이해해도 될 것 같습니다.
그럼, 정보의 유익함을 산출하는 기준은 무엇이냐는 질문을 할 수 있겠죠. 정보 이론에서는 발생 빈도, 확률이 낮은 사건이나 관측 데이터가 높은 정보량을 가진다고 정의합니다.

전혀 예상하지 못했던, 또는 기대하지 않았던 일이 발생했을 때와 늘상 반복되는 현상을 접했을 때, 둘 중 어느 것이 좀 더 기억에 크게 남던가요? 대부분의 사람들은 첫 번째 경우로 답하리라 믿습니다. 이런 단순하고 직관적인 논리에 따라, 정보 이론에서는 정보량과 사건의 발생확률을 반비례 관계로 봅니다.
좀 더 구체적으로는, 어떤 데이터 '$x$'에 대한 정보량 $I(x)$는 다음과 같이 로그함수 형태로 정의됩니다.
$$I(x) = -log(P(x))$$
로그 함수의 모양을 생각해보면, 사건 발생확률 P(x)에 대한 정보량 그래프는 아래에 보이는 것처럼 우하향 곡선 형태를 나타냄을 짐작 가능합니다.
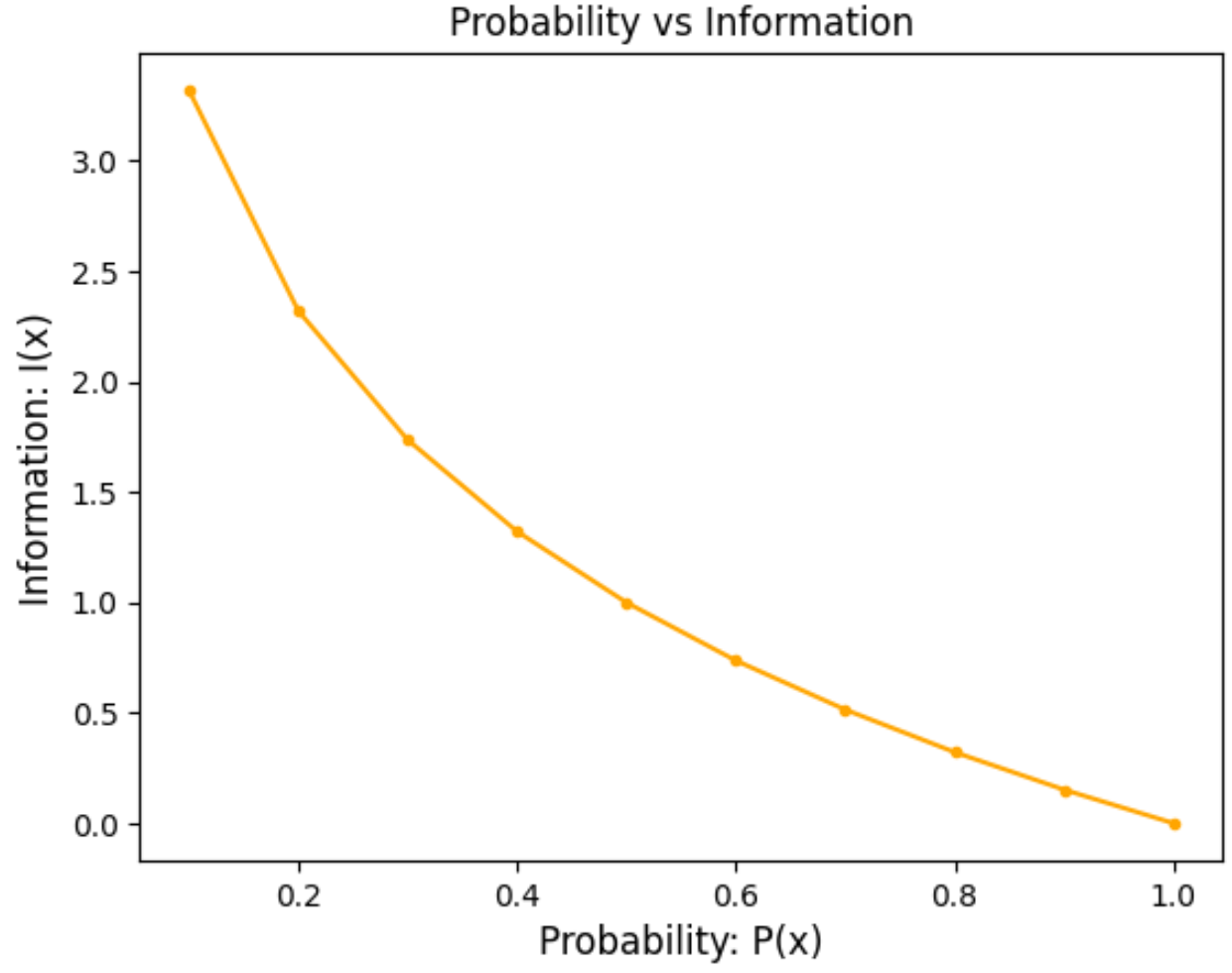
대게 로그 함수의 밑으로 ‘$2$’를 사용하게 되며, 이 경우 정보량을 표현하는 단위로 ‘bits’를 씁니다. 몇몇 확률에 대한 정보량을 계산해보면 아래 표와 같은 결과물을 얻을 수 있습니다. $P(x) = 1$과 같이 항상 발생하는 사건에 대해서는 중요도가 전무하다고 보는 셈이죠.
| 확률 P(x) | 정보량 I(x) |
| 0.1 | 3.322 bits |
| 0.5 | 1.000 bits |
| 1.0 | 0.000 bits |
2. 엔트로피 (Entropy)의 개념
정보 이론의 용어 중, 정보량에 버금갈 정도로 많이 쓰는 또다른 개념이 엔트로피 (Entropy)입니다. 원래 엔트로피라는 용어는 열역학에서 나왔으며, ‘무질서도’라는 명칭으로도 많이 알려져 있습니다.
정보량이 한 ‘사건’에 초점을 맞췄다면, 엔트로피는 모든 사건들을 포괄하는 확률 변수 X에 대한 정보 중요도를 수식화합니다.
$$H(X) = \Sigma_{x \in X}{P(x)I(x)} = -\Sigma_{x \in X}{P(x)\text{log}P(x)}$$
예시로, 주사위를 던지는 시뮬레이션에서의 엔트로피는
$$-\frac{1}{6}\text{log}\frac{1}{6} -\frac{1}{6}\text{log}\frac{1}{6} - ... -\frac{1}{6}\text{log}\frac{1}{6} = -6 \times \frac{1}{6}\text{log}\frac{1}{6} = -\text{log}\frac{1}{6} \approx 2.585 bits$$
확률 변수의 정보량을 왜 엔트로피, ‘무질서도’라는 명칭을 붙였는지는 명확하지 않으나, ‘무질서도’를 “각 사건의 발생확률이 얼마나 제멋대로인가”를 나타내는 수치로 정의를 내린다면 그 이유를 가늠해볼 수 있습니다.

일반적인 주사위처럼 각 눈이 나올 확률이 동일한 경우와 비교하여, 위 사진처럼 모양이 특이해 모든 눈이 정확하게 $\frac{1}{6}$의 확률로 등장하지 않는 주사위의 엔트로피가 어떻게 나오는지 확인해 봅시다.
정상 주사위
| P(x = 1) | P(x = 2) | P(x = 3) | P(x = 4) | P(x = 5) | P(x = 6) |
| 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
$$H(X) = \text{log}\frac{1}{6} \approx 2.585 \text{bits}$$
불량 주사위1
| P(x = 1) | P(x = 2) | P(x = 3) | P(x = 4) | P(x = 5) | P(x = 6) |
| 1/8 | 1/4 | 1/8 | 3/8 | 1/16 | 1/16 |
$$H(X) = \frac{1}{8}\text{log}\frac{1}{8} -\frac{1}{4}\text{log}\frac{1}{4} - ... -\frac{1}{16}\text{log}\frac{1}{16} \approx 2.281 \text{bits}$$
불량 주사위2
| P(x = 1) | P(x = 2) | P(x = 3) | P(x = 4) | P(x = 5) | P(x = 6) |
| 5/6 | 1/30 | 1/30 | 1/30 | 1/30 | 1/30 |
$$H(X) = \frac{5}{6}\text{log}\frac{5}{6} -\frac{1}{30}\text{log}\frac{1}{30} - ... -\frac{1}{30}\text{log}\frac{1}{30} \approx 1.037 \text{bits}$$
주어진 예시에서는 정상 주사위가 엔트로피값이 가장 높았고, 불량 주사위2처럼 확률이 극단적으로 차이가 나면 엔트로피가 낮아짐을 확인할 수 있습니다. 물론 실제로는 ‘엔트로피가 높다 = 무질서도가 높다’이고, 여기서는 완전히 거꾸로된 결과가 나오긴 했습니다만 상관관계가 작용한다고 봐야겠죠.
3. Cross-Entropy
머신러닝/딥러닝을 공부하면서 정말 많이 들어본 용어일 것입니다. 2장에서 정리한 Entropy가 확률 변수에 대한 평균 정보량이면, Cross-Entropy는 예측 분포와 실제 관측된 분포 간의 차이를 나타내는 정보량입니다. 어떤 확률 모형을 $X$를 예측하고자 할때의 Cross-Entropy는 다음과 같은 수식으로 표현 가능합니다.
$$H_{q}(X) = -\sum_{x \in X}{P(x) \text{log}Q(x)}$$
예를 들어, 확률 모형 '$X$'에서 발생 가능한 사건 범주가 $x = 1$ or $2$ or $3$이고 각각에 대한 실제, 그리고 우리가 예측한 확률분포가 아래 표와 같이 나온다고 해봅시다.
| x = 1 | x = 2 | x = 3 | |
| 실제 확률분포 P(x) | 0.5 | 0.3 | 0.2 |
| 예측 확률분포 Q(x) | 0.3 | 0.3 | 0.4 |
이 때의 Cross-Entropy는
$$H_{q}(X) = - 0.5\text{log}(0.3) - 0.3\text{log}(0.3) - 0.2\text{log}(0.4) \approx 1.654 \text{bits}$$
‘정보량 = 전혀 예상하지 못한 정도’이므로, 예측값과 실제값의 차이가 클수록 Cross-Entropy 값 역시 증가합니다. 위 사례에서는 ‘확률분포’를 예측한다고 설명을 달아 놓았습니다만, 머신러닝에서 사용되는 개념 ‘Cross-Entropy Loss’ 를 검색하려고 하셨던 분들은 고개가 살짝 갸우뚱해질 수 있을지도 모릅니다. 그쪽에서는 분포의 차이보다는, 시스템이 예측한 값과 실제 라벨/클래스 간의 차이 정도를 알고 싶어하기 때문이죠.
실제값(라벨 또는 클래스) ‘$y$’ 이에 대한 예측값 ‘$\hat{y}$’이 $N$개의 쌍으로 주어질 때, Cross-Entropy를 다음과 같이 정의하기도 합니다. 용어에 혼동을 피하기 위해서 ‘Categorical Cross Entropy’ 또는 클래스가 2종류뿐인 경우는 ‘Binary Cross Entropy’라는 표현으로 대체하기도 합니다.
Categorical Cross Entropy
$$CCE = -\frac{1}{N}\sum_{i = 1}^{N}\sum_{j = 1}^{C}{\ y_{ij} \ \text{log}(\hat{y}_{ij})}$$
실제값의 범주가 $C$개로 구분된다고 하면, 각각의 예측값과 실제값을 크기가 $C$인 one-hot encoding vector로 표현하게 됩니다. $y_{i}$는 $i$번째 데이터 샘플의 실제값, $y_{ij}$는 $i$번째 데이터의 라벨이 ‘$j$’이면 1, 그렇지 않을 경우는 0으로 나타냅니다. 그래서 $y$와 $\hat{y}$는 [[0,0,0,1, …, 0 ], [0,1,0,0, …, 0], …] 와 같은 행렬 형태로 표현합니다.
Binary Cross Entropy
$$BCE = -\frac{1}{N}\sum_{i = 1}^{N}{y_{i} \ \text{log}(\hat{y}_{i}) + (1 - y_{i}) \ \text{log}(1-\hat{y}_{i})}$$
$y$가 가질수 있는 값이 ‘$0$’ 또는 ‘$1$’, 두 가지 뿐일때의 Cross Entropy를 위와 같이 수식화합니다.
식에서 뒤에 있던 $\Sigma$ 하나가 날라가고 제일 앞의 $\Sigma$ 항에 식이 추가된 것처럼 보일지 모르지만, 사실 CCE에서 $C = 2$를 대입하여 $\Sigma_{j = 1}^{C}{y_{ij} \text{log}\ (\hat{y}_{ij})}$ 부분을 해체해보면 왜 BCE 식이 저렇게되는지 알 수 있습니다. $y_{i1} = 1$이면 자연스럽게 $y_{i2} = 0$가 성립하며, 그 반대도 마찬가지기 때문이죠. 그래서 그냥 $y_{i1}$, $y_{i2}$로 나누지 않고 $y_i$와 $(1-y_i)$로 치환한 것입니다.
▧ Note ▨
그런데 한 가지 걸리는 부분이 있습니다. 식에서 $\hat{y}_{ij} = 0$이면 $\text{log}$항이 음의 ∞ 가 될텐데 Cross Entropy 식을 저렇게 모델링해도 괜찮을까요?
이러한 우려를 방지하기 위해서 보통 $\text{log}$항 안에 특수한 함수 ‘$f(\hat{y}_{ij})$’를 사용하게 됩니다. BCE의 경우에는 ‘Sigmoid’라는 함수를, CCE는 ‘Softmax’라는 함수를 말이죠.
\begin{align} &CCE = -\frac{1}{N}\sum_{i = 1}^{N}\sum_{j = 1}^{C}{y_{ij} \ \text{log}(f(\hat{y}_{ij}))}, \\&BCE = -\frac{1}{N}\sum_{i = 1}^{N}{y_{i} \ \text{log}(f(\hat{y}_{i})) + (1 - y_{i}) \ \text{log}(f(1-\hat{y}_{i}))} \end{align}
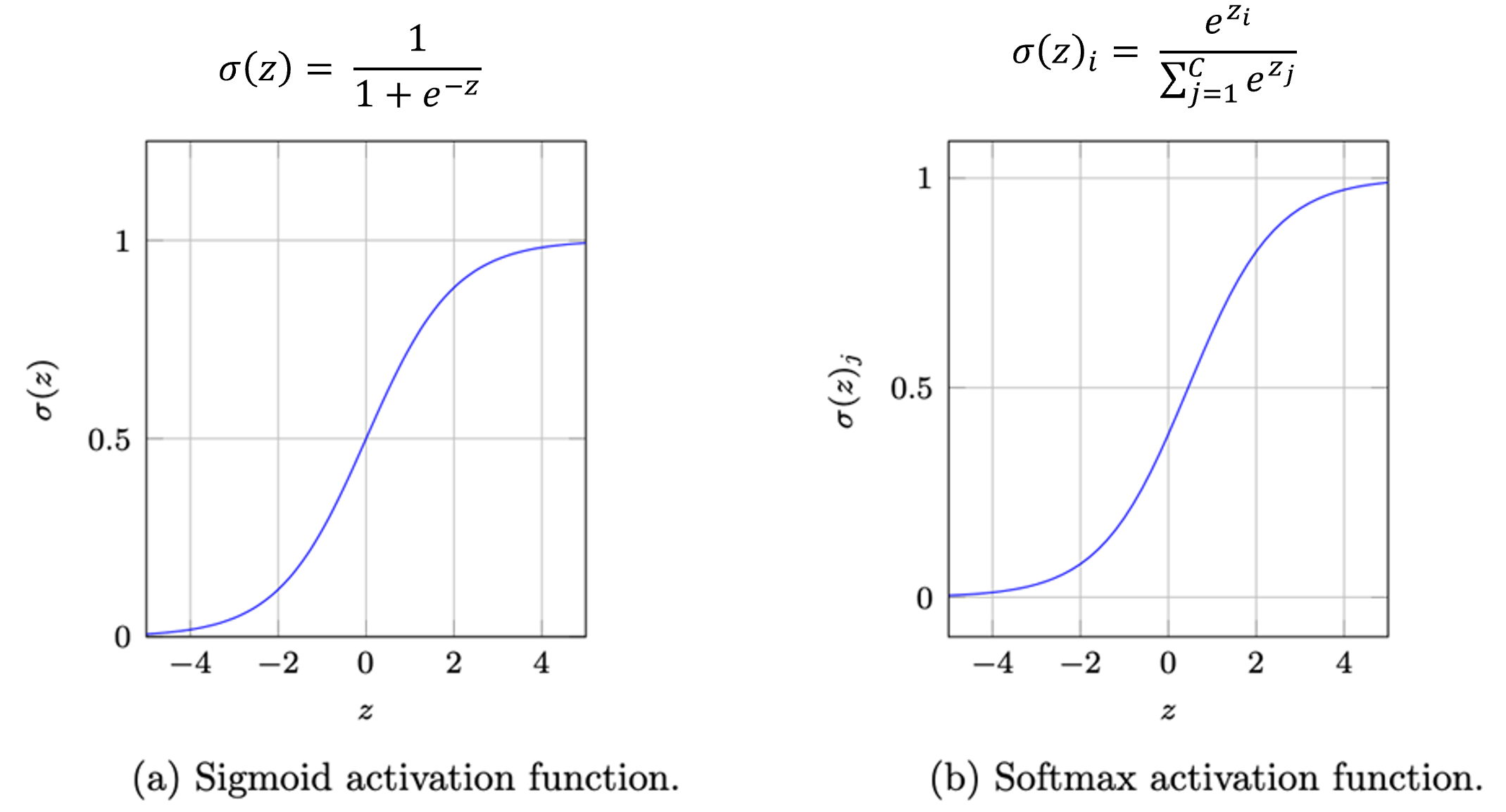
일단 이렇게라도 해두면, 최소한 Cross Entropy가 ∞로 산출되는 일은 방지할 수 있습니다.
4. KL divergence
KL divergence(Kullback-Leibler divergence)는 Cross Entropy와 마찬가지로, 확률 모형에 대한 예측 분포와 실제 분포의 차이를 비교하는 함수입니다. 실제로 식의 구조가 Cross-Entropy와 상당히 유사합니다.
- Cross-Entropy: $H_{q}(X) = -\Sigma_{x \in X}{P(x) \text{log}Q(x)}$
- KL divergence: $D_{KL}(P\ ||\ Q) = -\Sigma_{x \in X}{P(x) \text{log}\frac{P(x)}{Q(x)}}$
KL divergence 식을 풀어보면 다음과 같은 등식을 얻을 수 있습니다.
\begin{align} D_{KL}(P\ ||\ Q) &= -\sum_{x \in X}{P(x) \ \text{log}\frac{P(x)}{Q(x)}}\\\\&= -\sum_{x \in X}{P(x)(\text{log}P(x) - \text{log}Q(x))} \\\\&= -\sum_{x \in X}{P(x) \text{log}P(x) +\sum_{x \in X} P(x) \text{log}Q(x) } \\\\&=H(X) - H_{q}(X)\end{align}
즉, $X$의 실제 정보량에서 Cross-Entropy를 뺀 값이 KL divergence가 되는 것이죠.
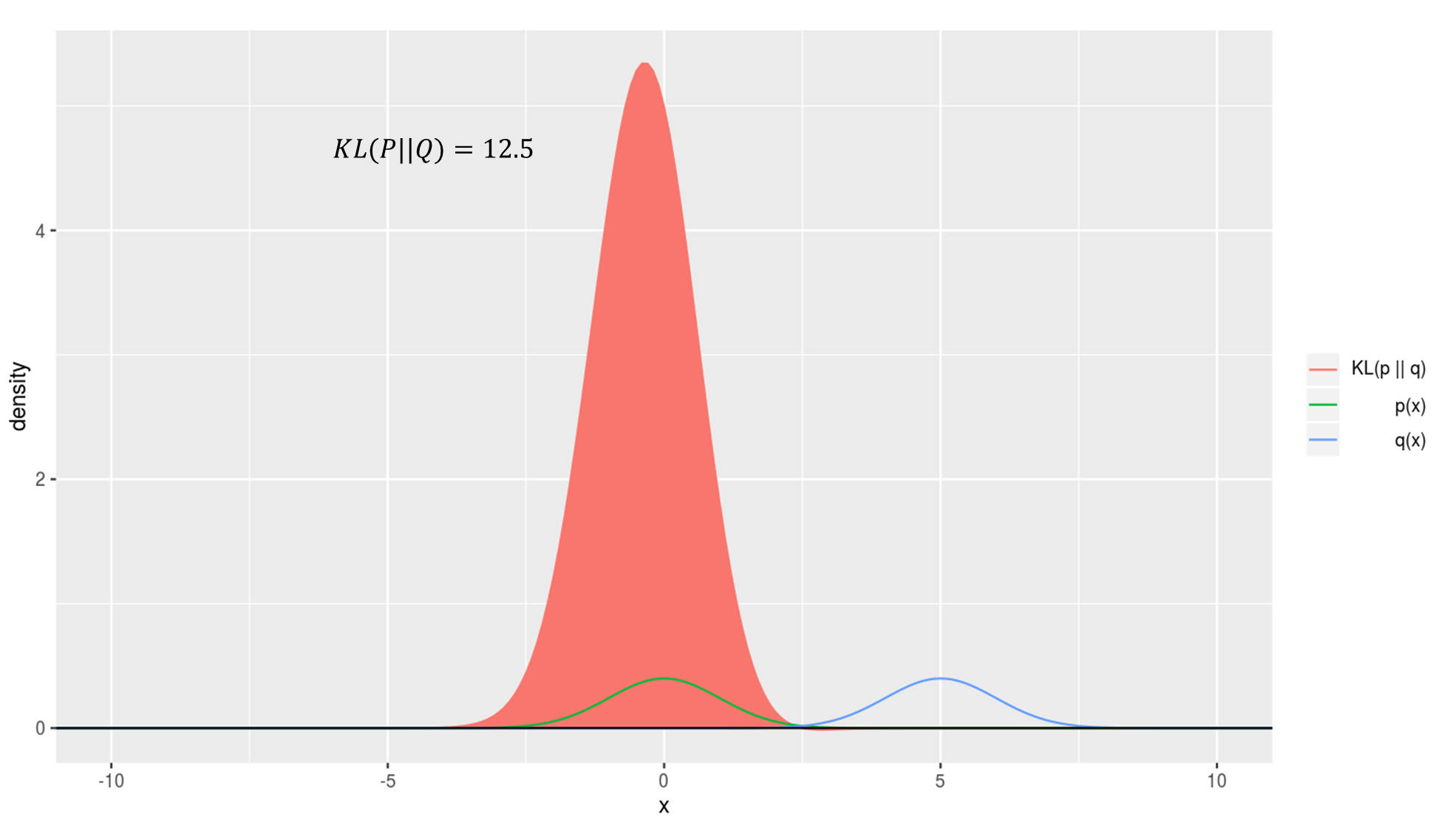
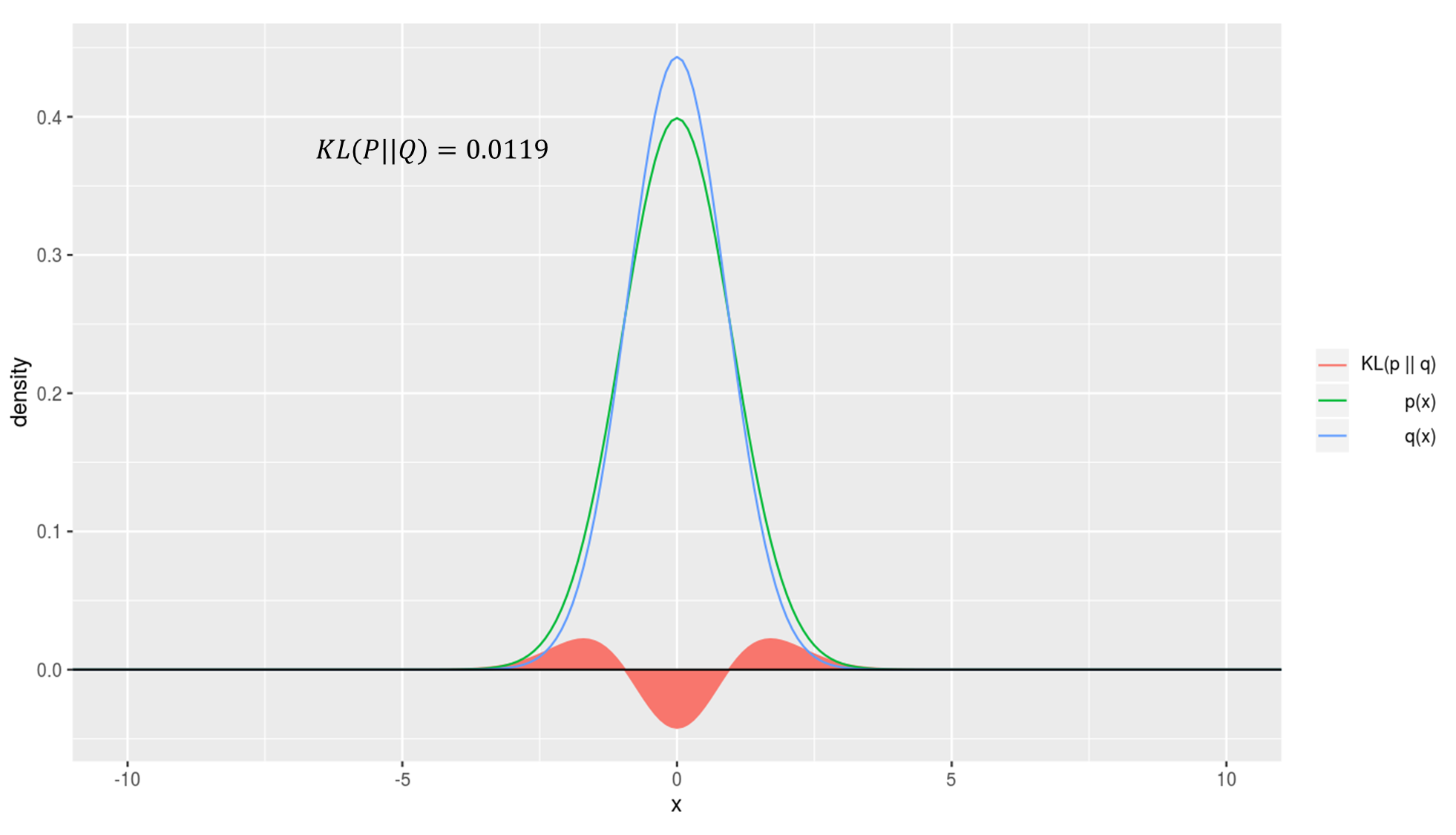
KL divergence를 시뮬레이션한 결과를 확인해보시면 이해에 도움이 되실겁니다. 아래 그래프에서 초록색 선은 실제 확률분포, 파란선은 예측 확률분포, 그리고 빨간 영역의 넓이가 곧 KL divergence 값이 됩니다.
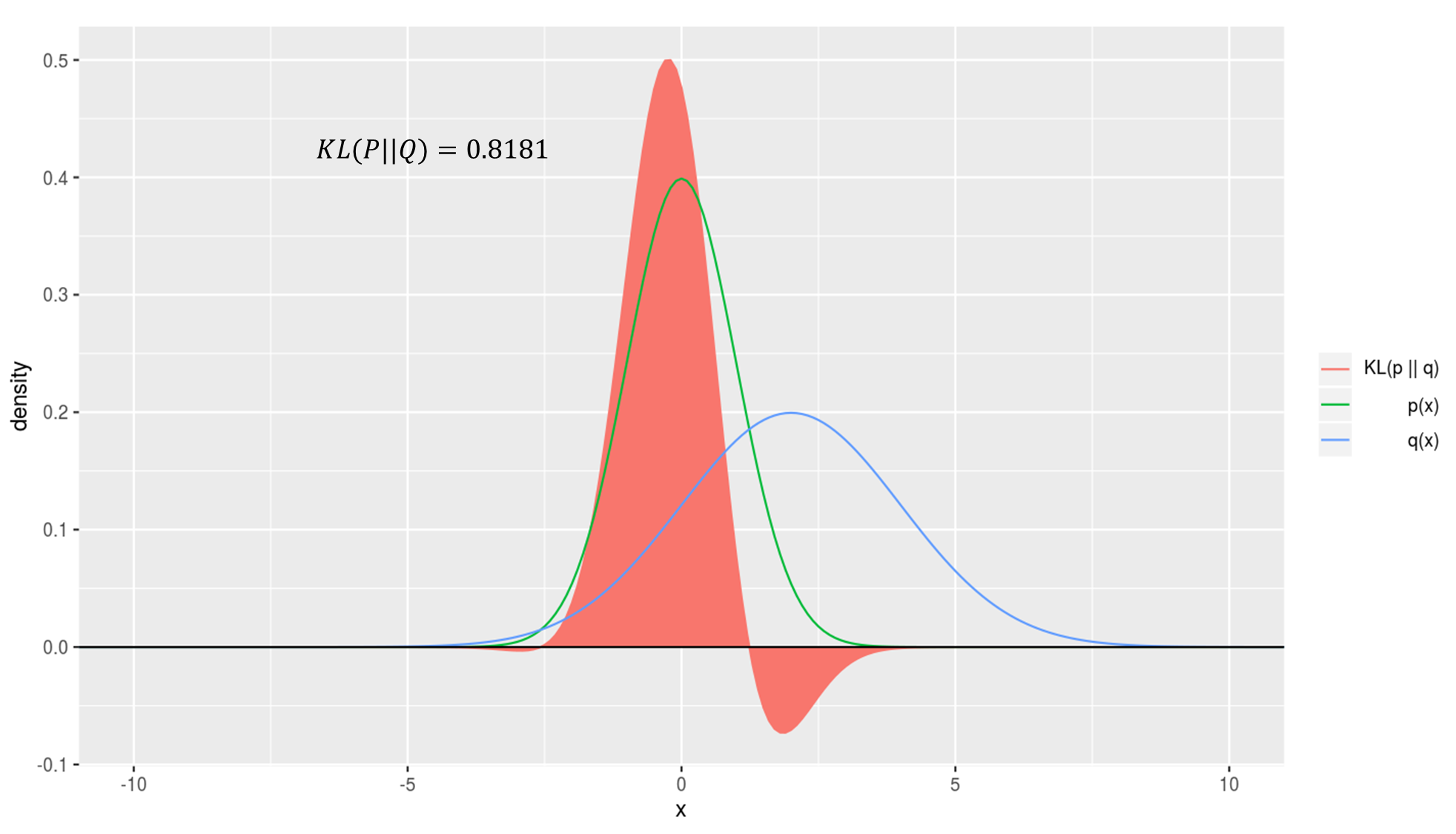
예측이 실제와 매우 일치할때
예측이 실제와 전혀 일치하지 않을때