그림 그려주는 AI, 그 중에서 꽤나 Hot한 관심을 받은 Stable Diffusion이 웹 버전으로 나왔습니다. 따로 가입이나 유료 결제 없이 웹 브라우저에서 쉽게 AI 그림을 생성할 수 있도록 편리함을 제공하였는데요. 이번 포스트에서는 Stable Diffusion Web UI를 설치하고 활용하는 방법을 수록하였습니다.
1. 요구 사양
개인 컴퓨터의 GPU로 AI를 돌려야하다보니 쓸만한 그래픽 카드가 달려있긴 해야합니다. 노트북보다는 데스크탑 사용을 권장드리구요, 적정 그래픽 카드 메모리는 4GB 이상이라고 하니 개인 PC에 부착된 그래픽 카드의 사양을 확인해보시기 바랍니다.

2. Stable Diffusion 설치
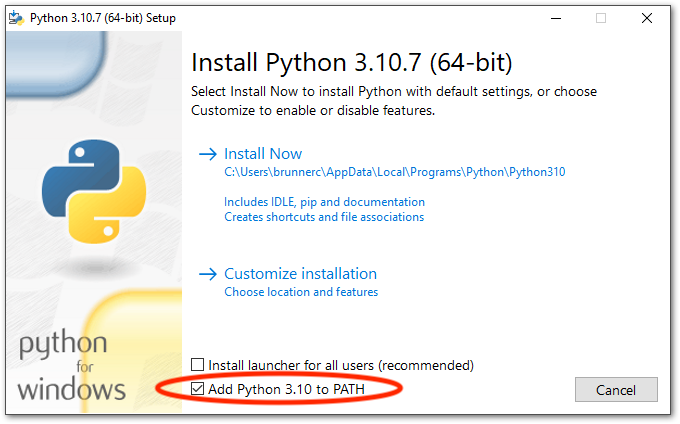
Python 설치 (3.10.6 버전 이상)
Python이 뭐하는 건지 잘 모르셔도 됩니다.. 일단 아래 주소에서 파이썬 설치 파일을 다운받아 설치부터 하고 봅니다. 초기 설치화면에서 제일 하단 박스 "Add Python 3.10 to PATH"를 체크해주세요.
https://www.python.org/ftp/python/3.10.11/python-3.10.11-amd64.exe
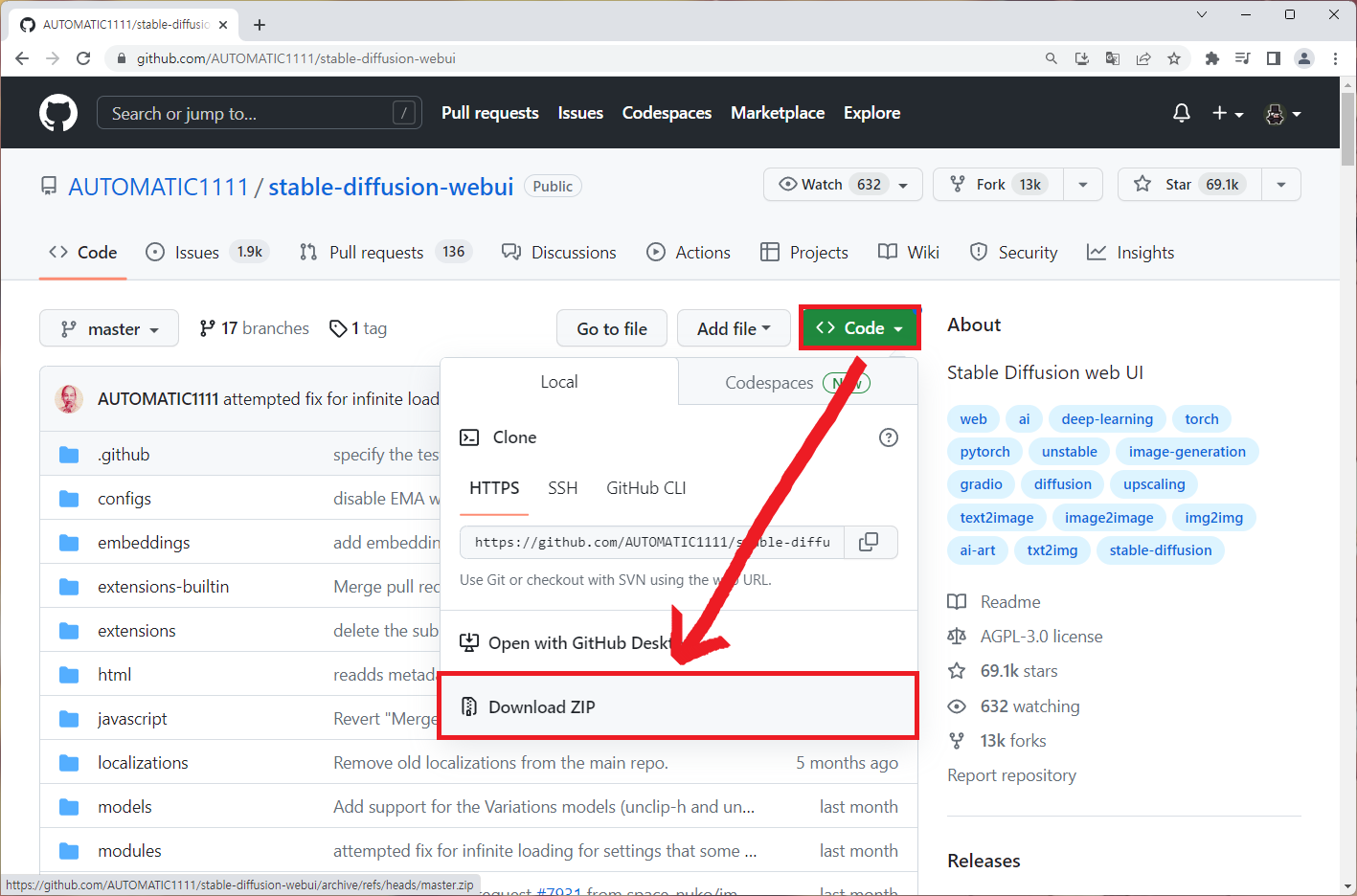
Stable Diffusion 압축 파일 다운로드
아래 주소로 들어가서 초록색 Code 버튼 클릭 >>> Download ZIP 선택하여 파일을 내려 받은 뒤, 압축을 풉니다.
https://github.com/AUTOMATIC1111/stable-diffusion-webui
GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
github.com
Web UI 실행
압축을 푼 폴더로 들어가 webui-user 파일을 실행시킵니다.
까만 창이 나오면서 추가 설치파일을 다운로드 받으니 여유를 갖고 기다립니다.
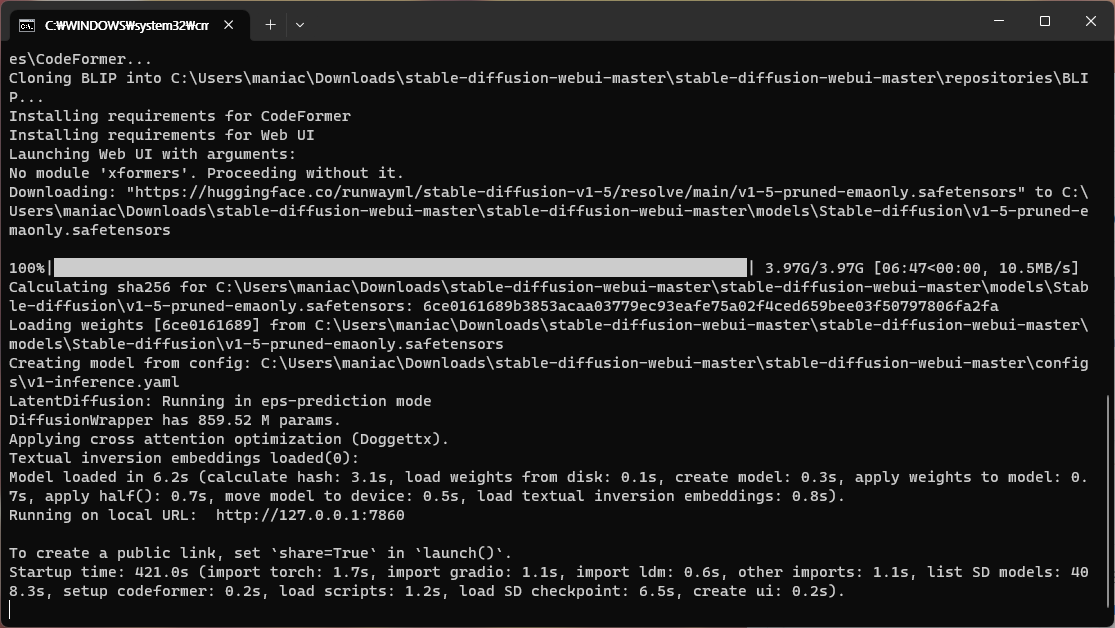
브라우저로 Web UI 접속
브라우저 주소창에 localhost:7860을 입력하면 Stable Diffusion Web UI 페이지가 나타나게 됩니다.
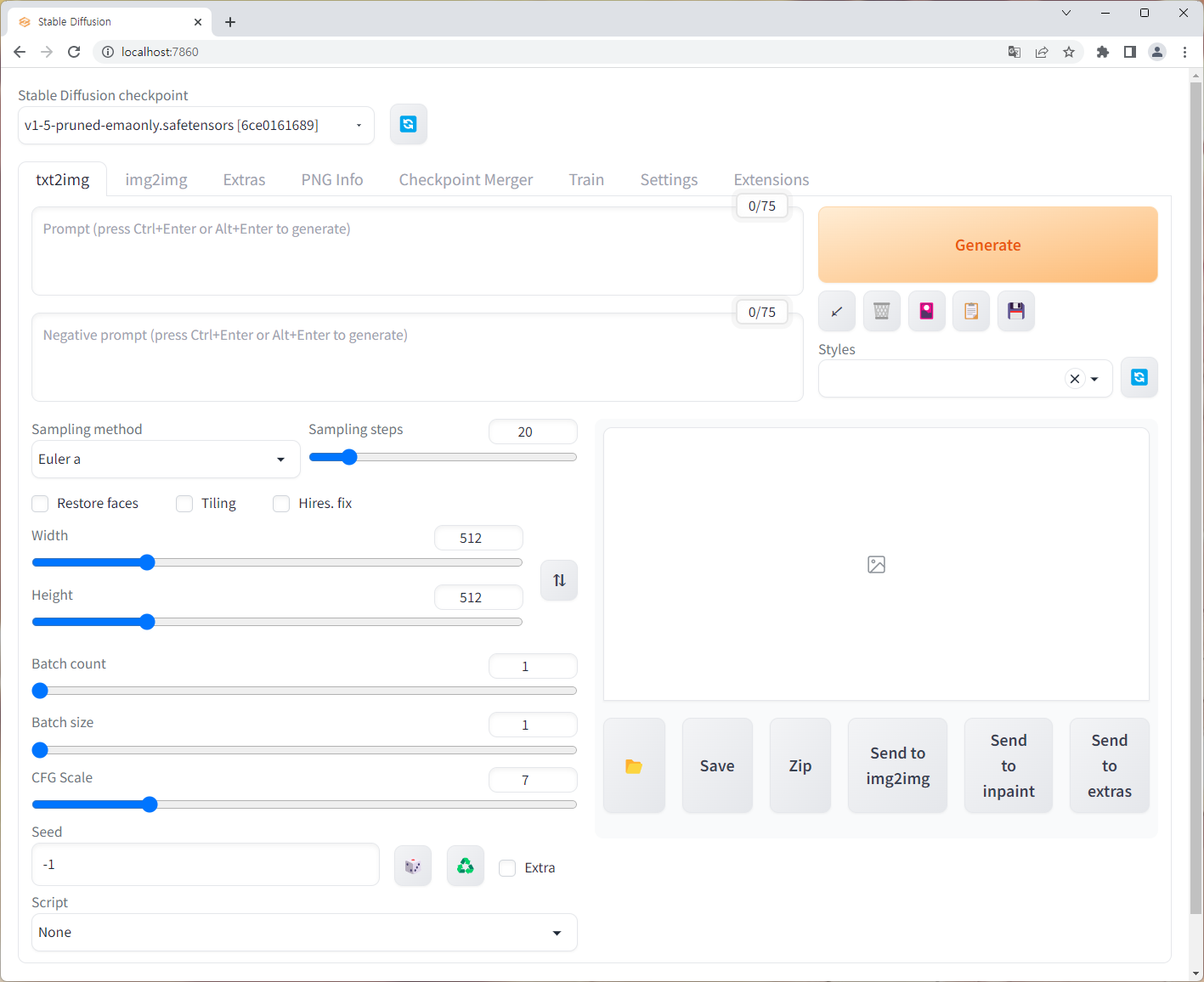
3. AI 모델 다운로드
Web UI까지 설치했지만, 아직 추가로 해야하는 준비 작업이 있습니다. AI 모델을 다운 받는 것인데요.
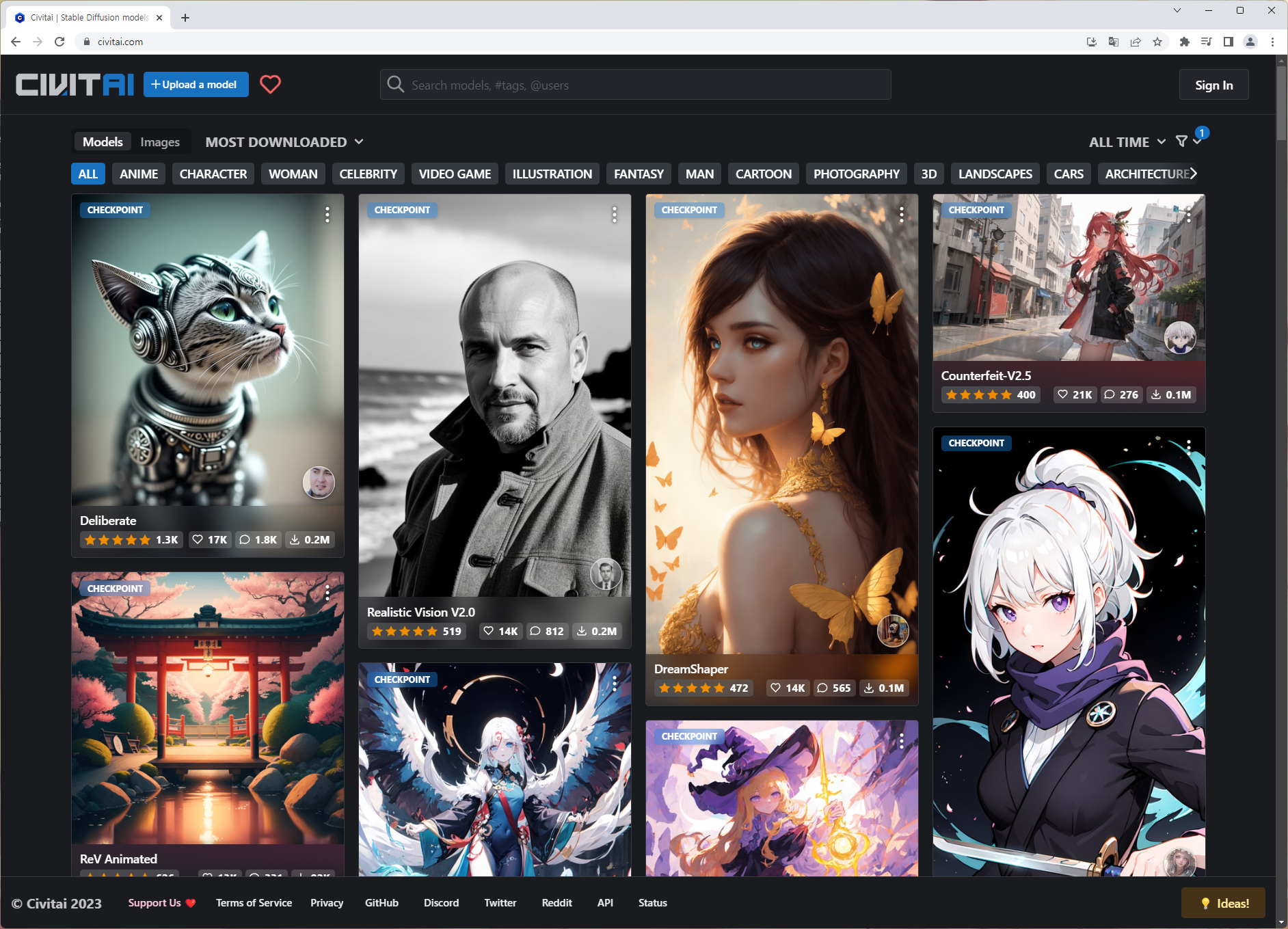
AI 모델이라 함은, 어떤 화풍(실사, SF, 디즈니, 만화 등)으로 그림을 그려낼 것인지 결정해주는 프리셋 정도라고 생각하시면 됩니다. 이 모델 데이터는 Civitai라는 곳에서 다운로드 받을 수 있습니다.
Civitai | Stable Diffusion models, embeddings, LoRAs and more
Civitai is a platform for Stable Diffusion AI Art models. Browse a collection of thousands of models from a growing number of creators. Join an engaged community in reviewing models and sharing images with prompts to get you started.
civitai.com
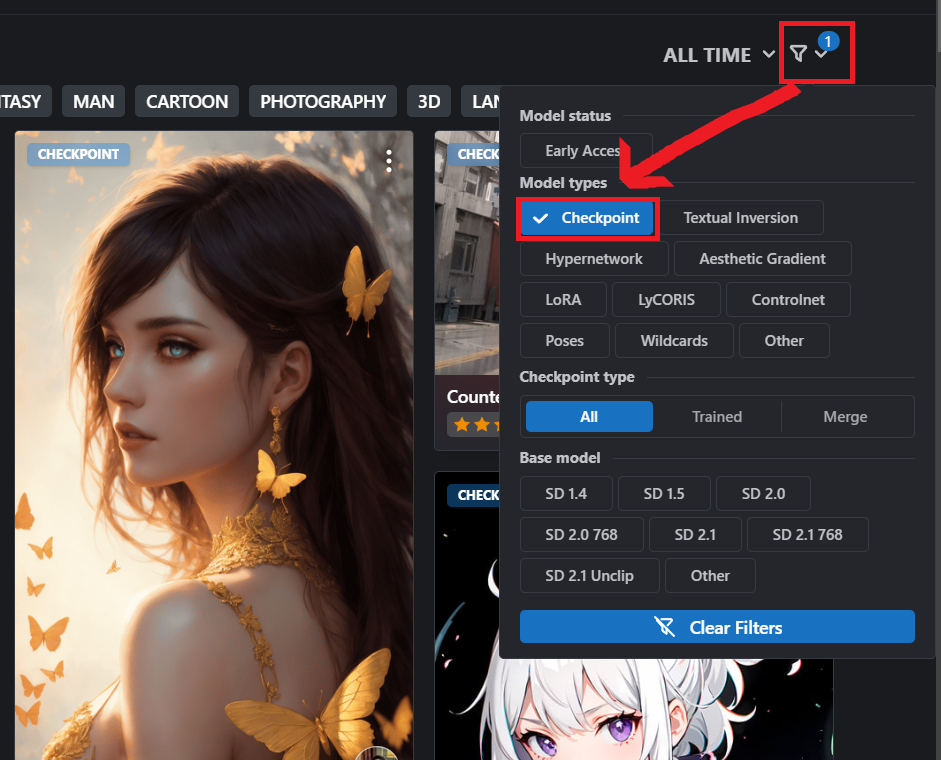
우측 상단 필터링 옵션에서 Checkpoint를 선택합니다.
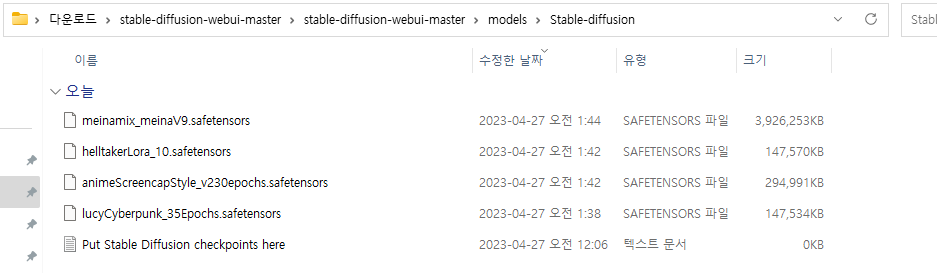
마음에 드는 AI 모델을 찾아 다운받고, 이를 [stable diffusion 압축푼 폴더]\models\Stable-diffusion 경로에 집어 넣어주세요.

다시 UI로 돌아와 상단 새로고침 버튼을 클릭한 뒤, 다운받은 AI 모델을 선택합니다.

4. 이미지 생성
이미지 생성 방식은 크게 txt2img와 img2img가 있습니다.
txt2img
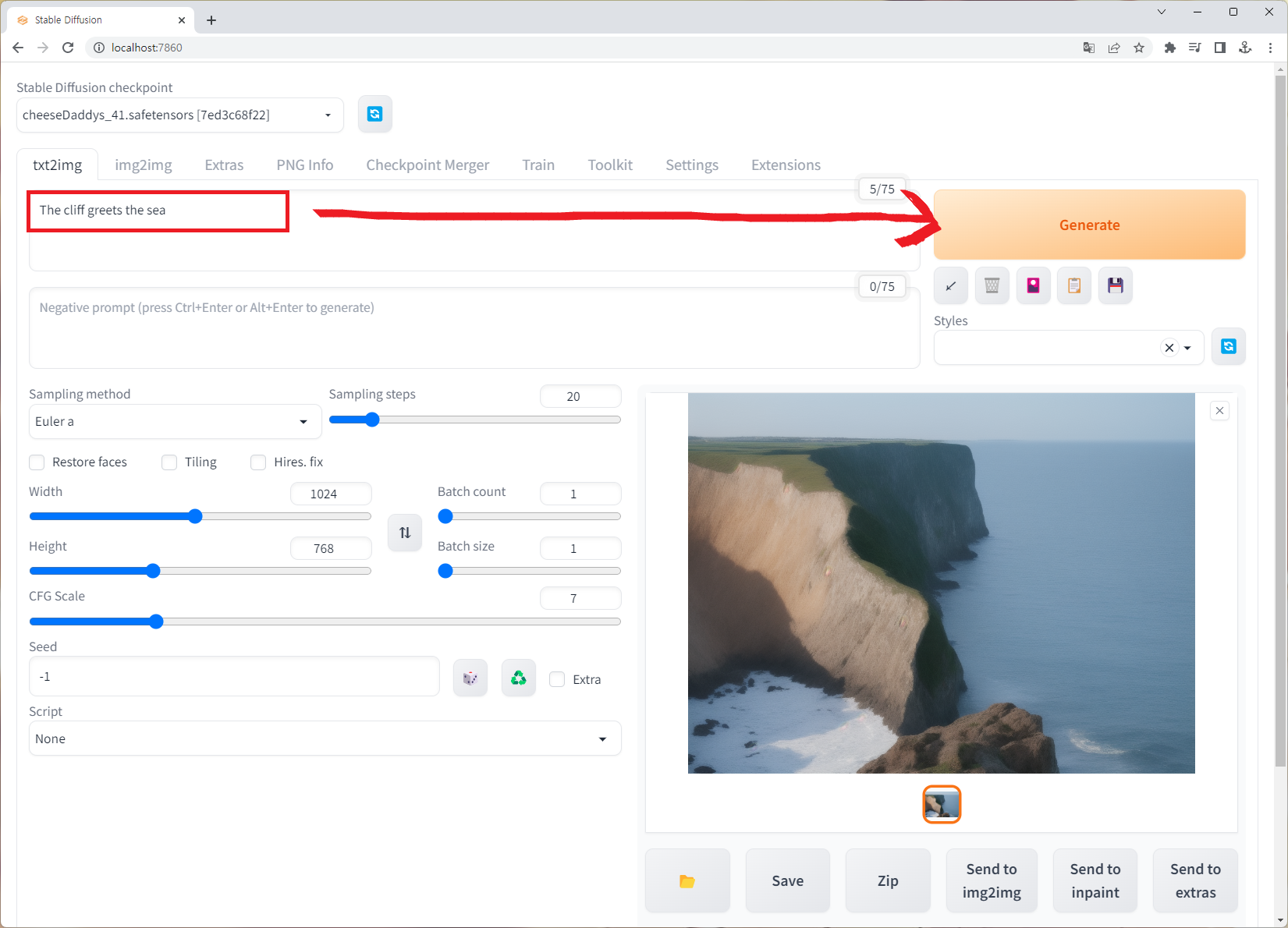
그림으로 표현하고자하는 문장을 던져주고 AI 모델을 돌려 가상의 그림을 생성해냅니다. 상단에는 키보드 입력이 가능한 텍스트 공간이 위아래로 2개(Prompt, Negative prompt)가 있습니다.
Prompt는 표현하고자 하는 이미지 정보를 문장으로 작성하는 공간이고, Negative prompt는 그림에서 표현되지 않았으면 하는 오브젝트나 디자인을 입력받는 영역입니다. Negative prompt는 인물을 그릴때 손 또는 손가락 개수가 안 맞다던가하는 오류를 어느 정도 잡아줄 수 있다고 합니다.
그 아래에는 Sampling method, Seed 등의 기타 그림 생성 옵션이 있는데 사실 가로, 세로 크기 외에는 꼭 건들 필요는 없습니다. 다만 조금씩 조정하다보면 좀 더 다채로운 그림들을 얻을 수 있습니다.
예시에서는 Prompt 부분에 "The cliff greets the sea (바다와 맞닿아 있는 절벽)"이라는 문장을 입력하여 그림을 생성하였습니다. 사용한 모델은 Cheese Daddy's Landscapes mix 입니다.
아래는 몇 가지 추가적인 예시를 가져와봤습니다.

AI 모델: Deliberate
Prompt: Bear Grylls, taking picture with a Grizzly, self camera, blue sky, summit
Negative prompt: -
Sampling method/steps: DDIM/28
Width/Height: 768/512

AI 모델: Counterfeit-V2.5
Prompt: blue denim jacket, white t-shirt, short pants, side ponytail, smiling, sitting on a chair, coffee
Negative prompt: low quality, worst quality, extra arms, text, disembodied, fused fingers, lowres, cropped, bad hands
Sampling method/steps: Euler a/20
Width/Height: 768/1024
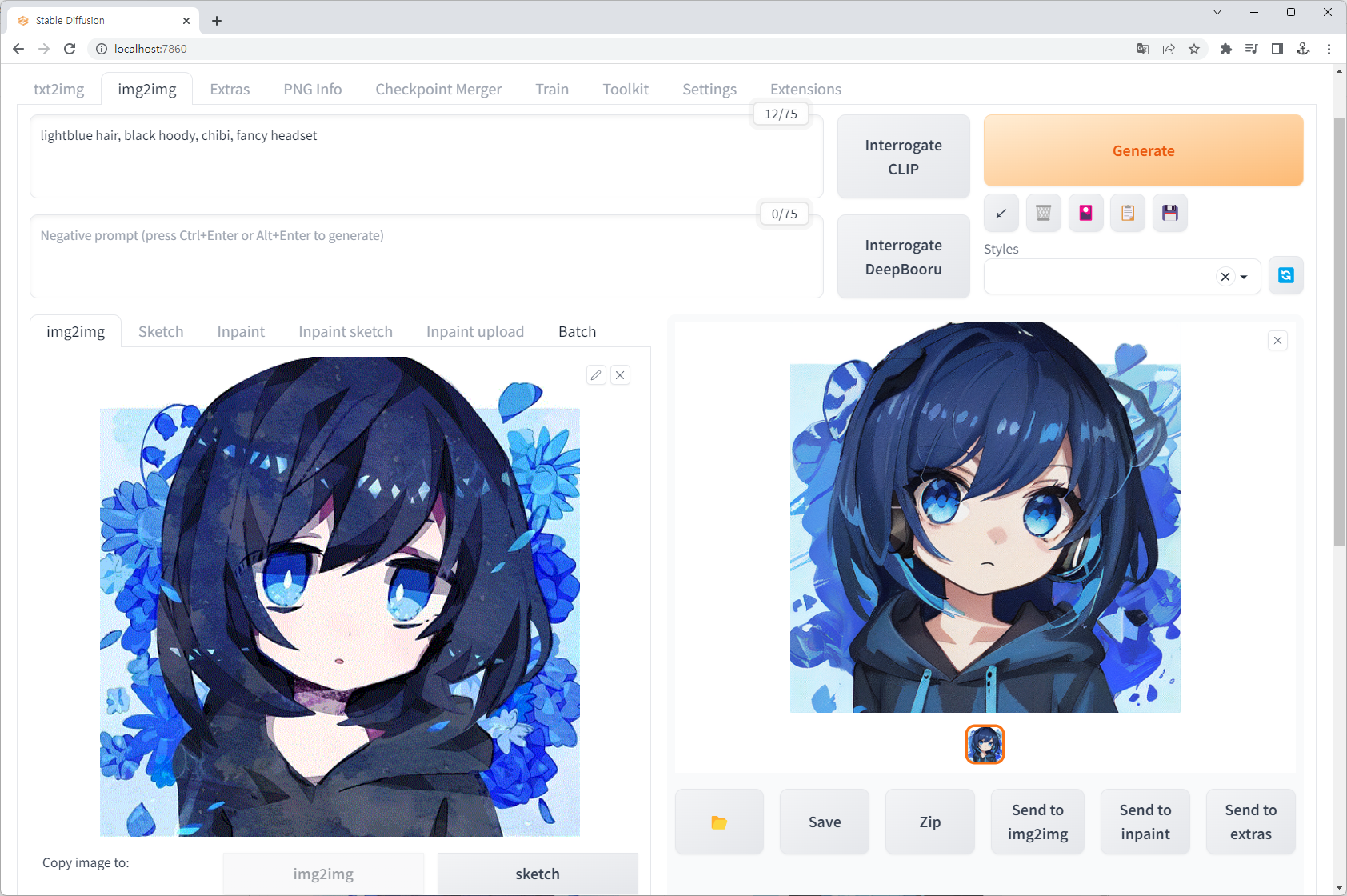
img2img
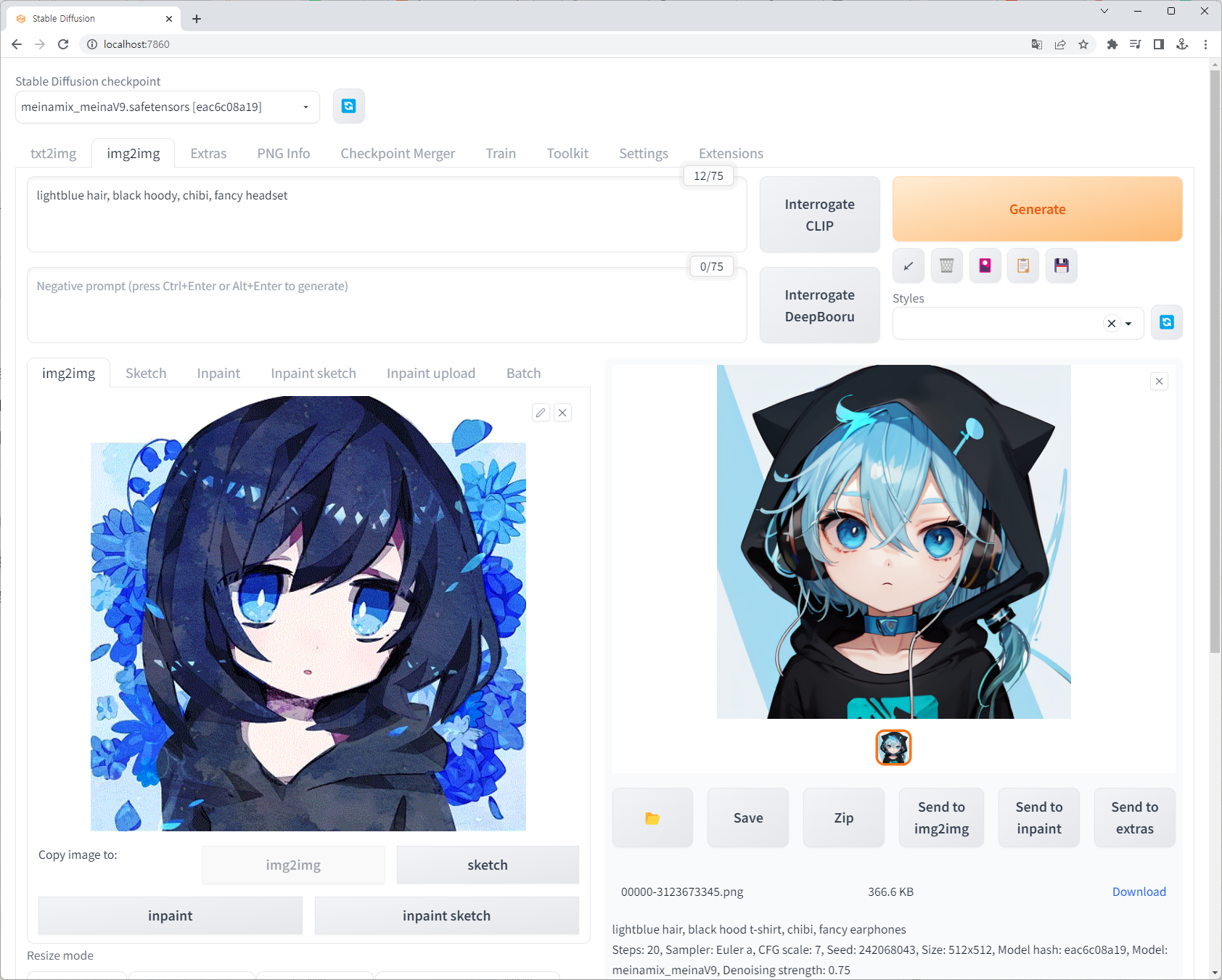
기존에 이미 있는 이미지를 참고하여 새로운 AI 이미지를 생성해주는 기능입니다. txt2img와 동일하게 원하는 그림 형태를 문장(단어 여러개를 콤마로 구분하여 나열해도 상관없습니다)으로 입력해주면, 기존 이미지와 해당 문장을 잘 조합하여 그림으로 표현해줍니다. 본 예시에서 사용한 모델은 MeinaMix 입니다.
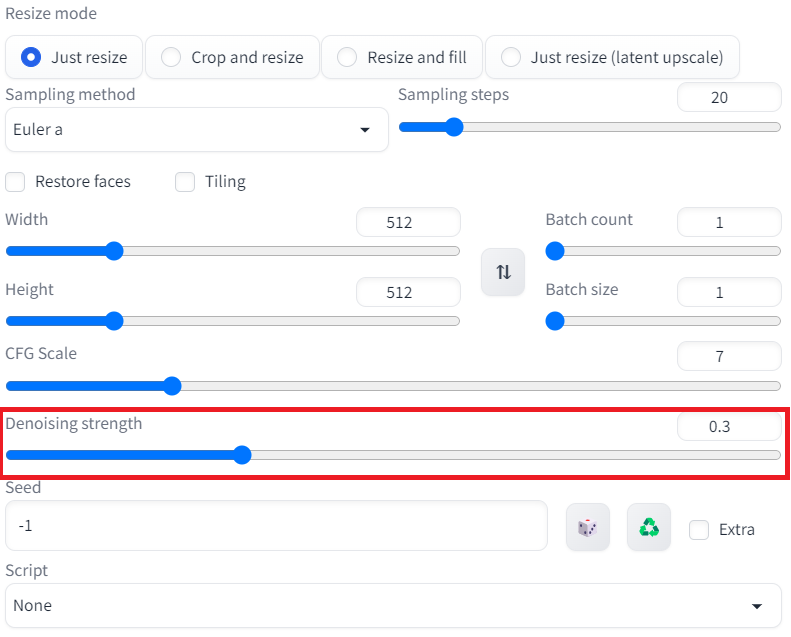
옵션 조정 박스 제일 아래에 'Denoising strength'라는 항목이 있을텐데요. 이 값을 줄이면 참고할 이미지와 최대한 비슷한 그림을 얻을 수 있습니다. 직전의 그림은 Denoising strength 값을 0.75로 설정했을 때의 결과물이고, 이를 0.3 정도로 낮춰보면 아래와 같이 원본과 상당히 유사한 그림이 탄생합니다.