1. 데이터 준비
시각화할 데이터를 서비스에 올리기 위해서 아래의 3가지 방법을 이용할 수 있습니다.
- Kibana 웹 인터페이스에서 직접 데이터 업로드 (
csv,tsv,json등의 데이터 포맷 허용) - 터미널 또는 프롬프트에서 Elasticsearch REST API로 데이터 업로드 (
json포맷) - Logstash로 파일을 읽어들여서 Elastic Engine에 저장
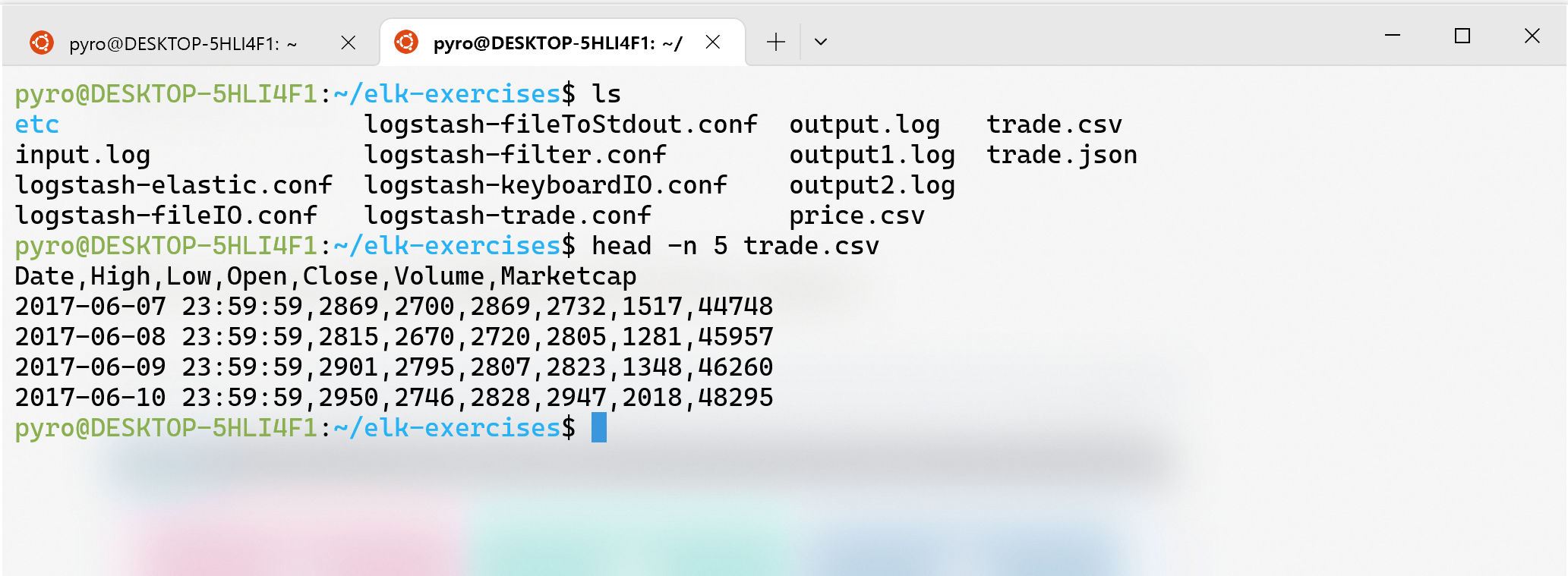
위 3가지 케이스들을 하나씩 테스트해보기 위해서 데이터 샘플을 준비하였습니다. 아래의 데이터는 2017~2021년 사이의 Bitcoin 거래 통계를 매주마다 기록한 리스트입니다.
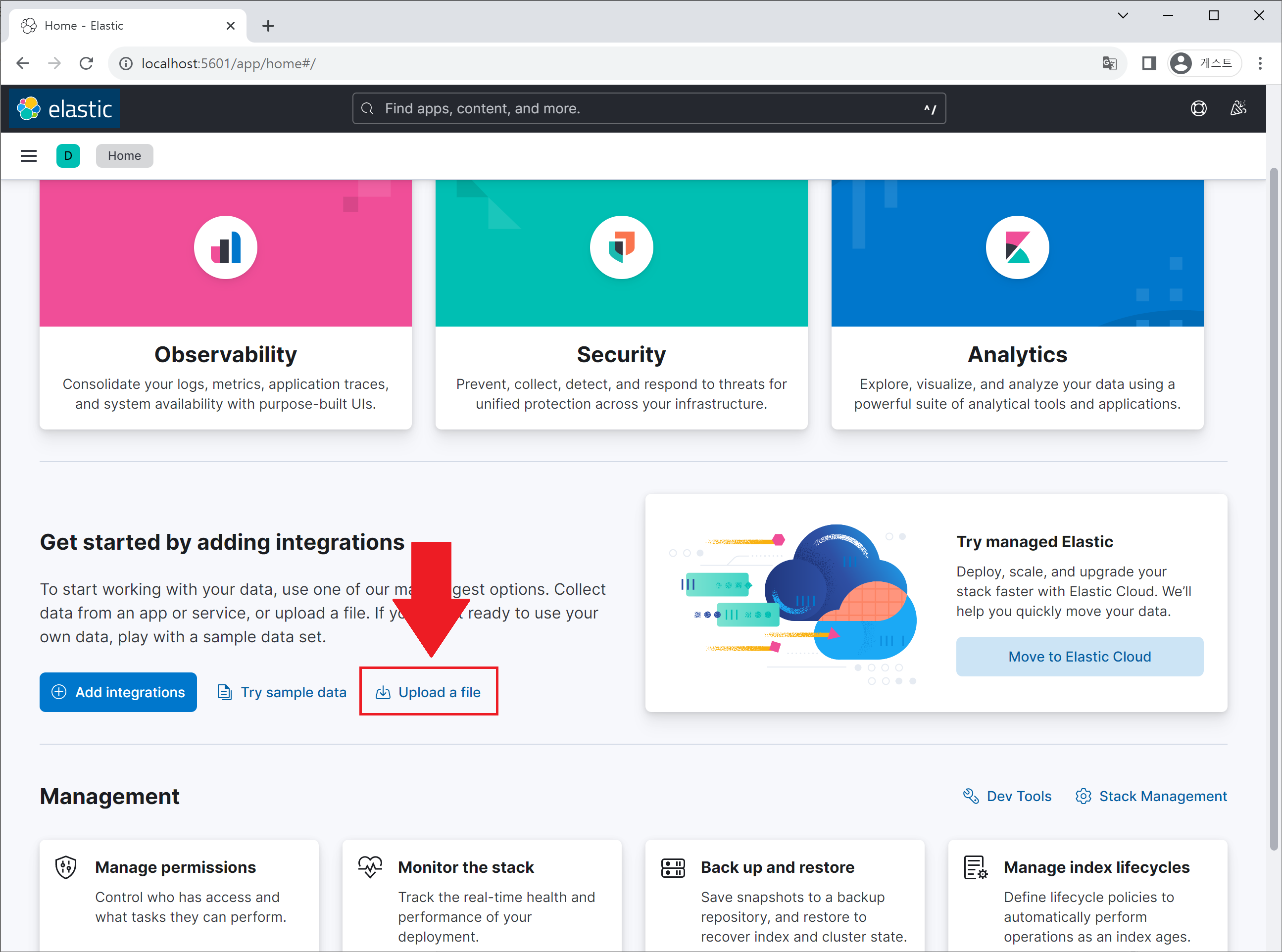
방식 A: Kibana 웹 인터페이스에서 데이터 업로드
터미널에서 명령어를 입력할 필요도 없고, 드래그 앤 드롭으로 곧바로 데이터를 올리는 방법입니다. 기본 home 페이지에서 ‘Upload a file’ 텍스트를 클릭합니다.
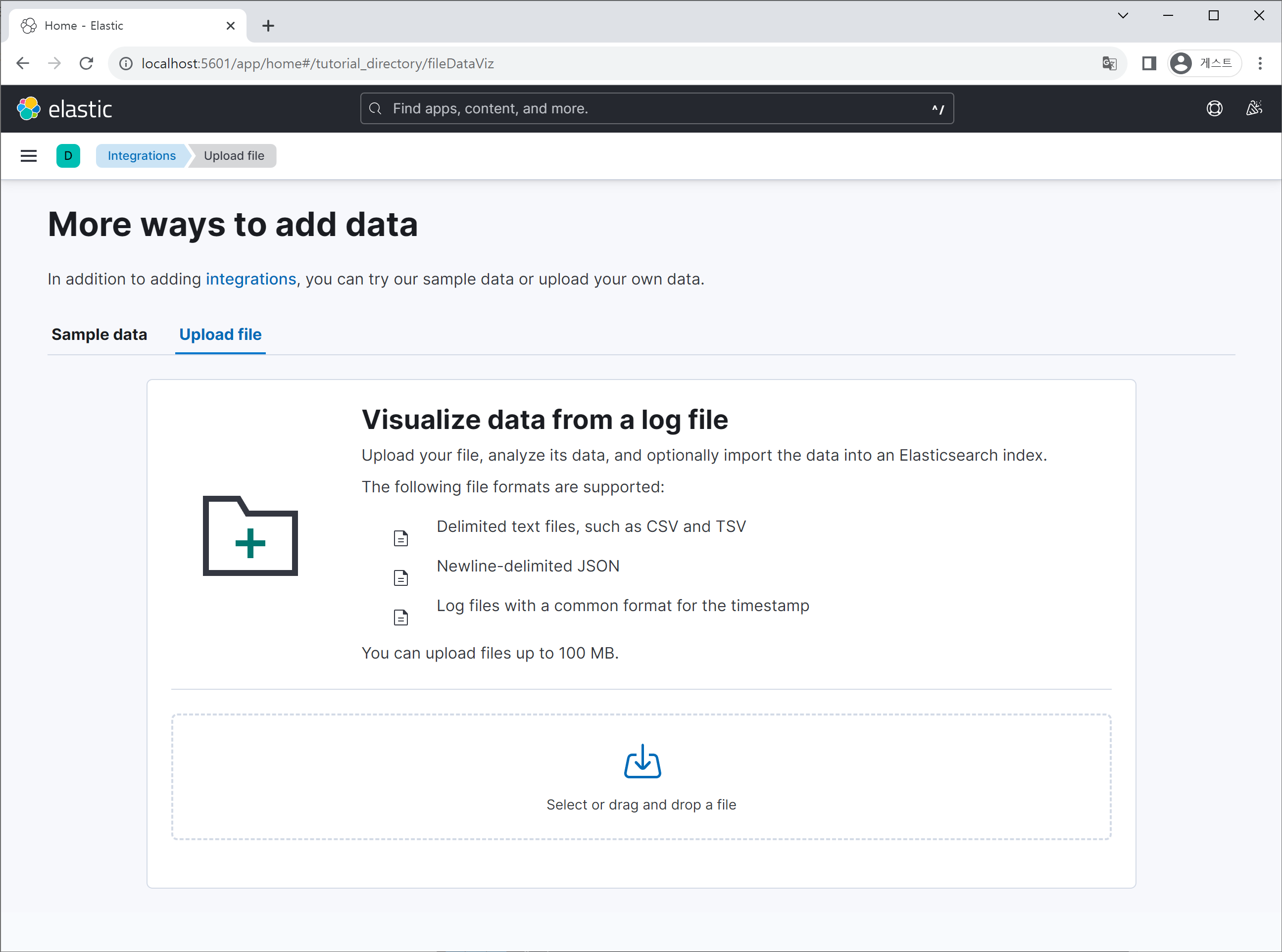
데이터 파일을 선택하고, 하단에 나오는 Import 버튼을 클릭합니다.
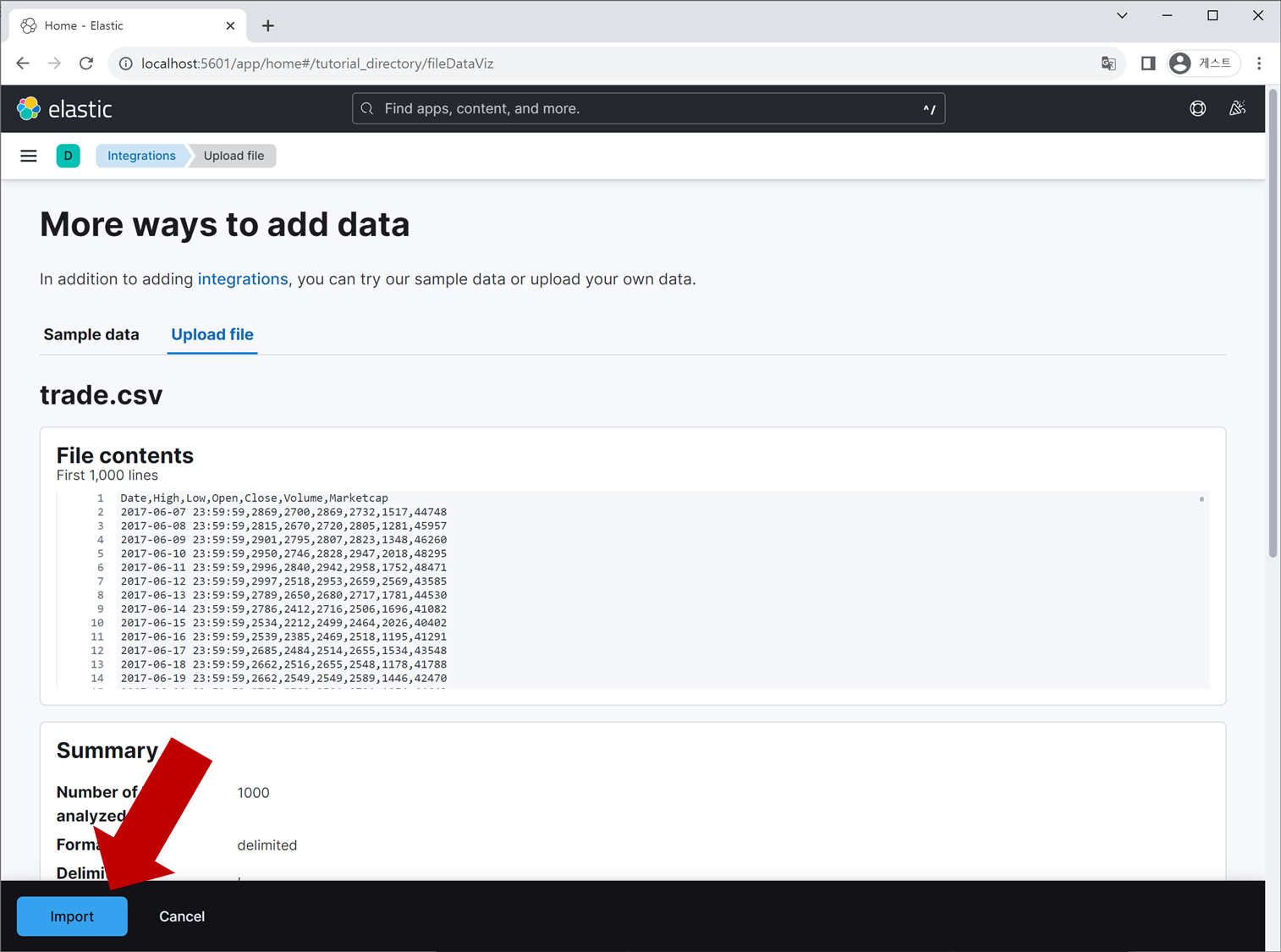
Advanced 탭을 클릭 후, Index name 및 Data view name 항목을 입력합니다. Import 버튼을 누르면 elasticsearch DB에 기입했던 Index가 생성되고, 방금 업로드한 데이터들이 해당 Index에 저장됩니다.
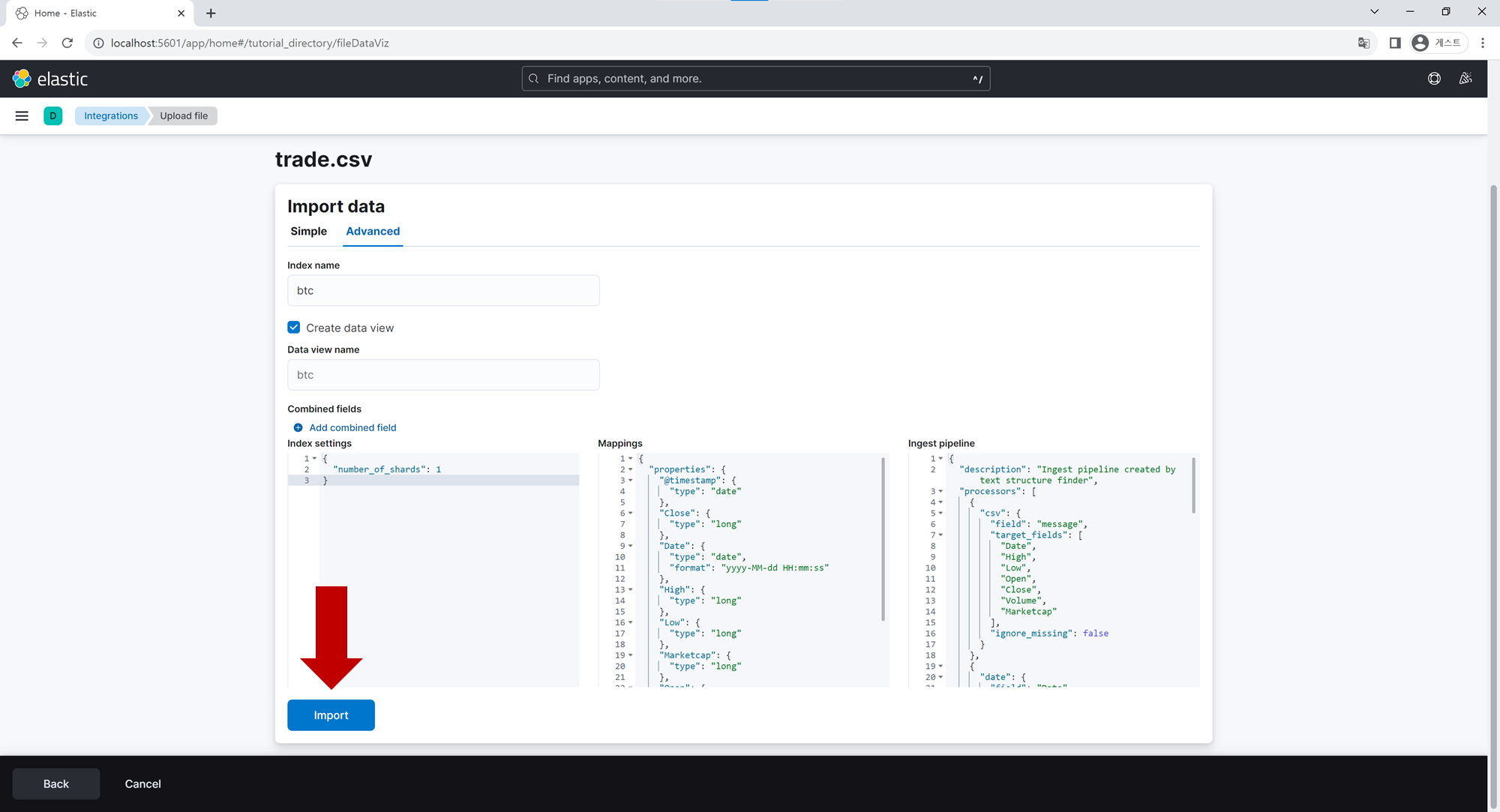
View index in Discover 버튼을 클릭하여 Elastic 엔진에 등록한 데이터를 확인해 봅니다.


방식 B: 터미널에서 Elasticsearch API로 데이터 업로드
RESTful API를 이용하여 터미널에서 직접 데이터 파일을 Elastic DB에 등록합니다. 데이터가 특정 Index에 저장이되면, Kibana에 Elasticsearch의 index들이 자동으로 갱신되어 데이터를 조회해볼 수 있습니다.
다만 방식 A처럼 csv, log 형태의 파일을 직접 보내기는 어렵고 대신 json 포맷을 이용해야하는 번거로움이 존재합니다.
# trade.json이 있는 디렉토리에서
$ curl -XPUT http://localhost:9200/test02
$ curl -XPOST http://localhost:9200/_bulk --data-binary @trade.json \
-H 'Content-Type: application/json'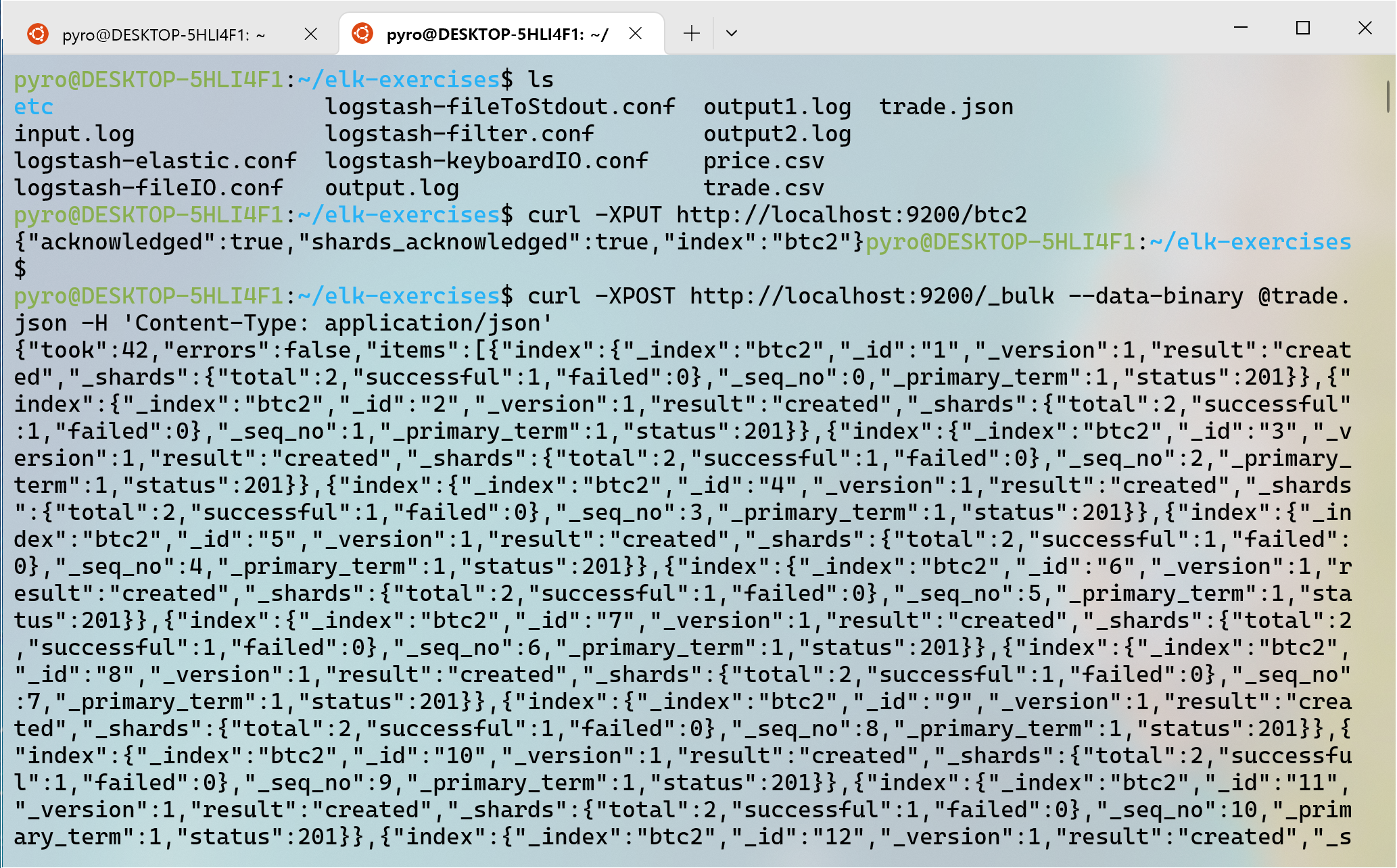
Elasticsearch에 데이터가 저장되었으니 이제 Kibana 웹페이지로 돌아가 Data View를 다시 생성할 것입니다. Kibana의 우측 상단 메뉴 아이콘 ≡ 을 클릭 > Analytics > Discover 탭으로 들어갑니다.
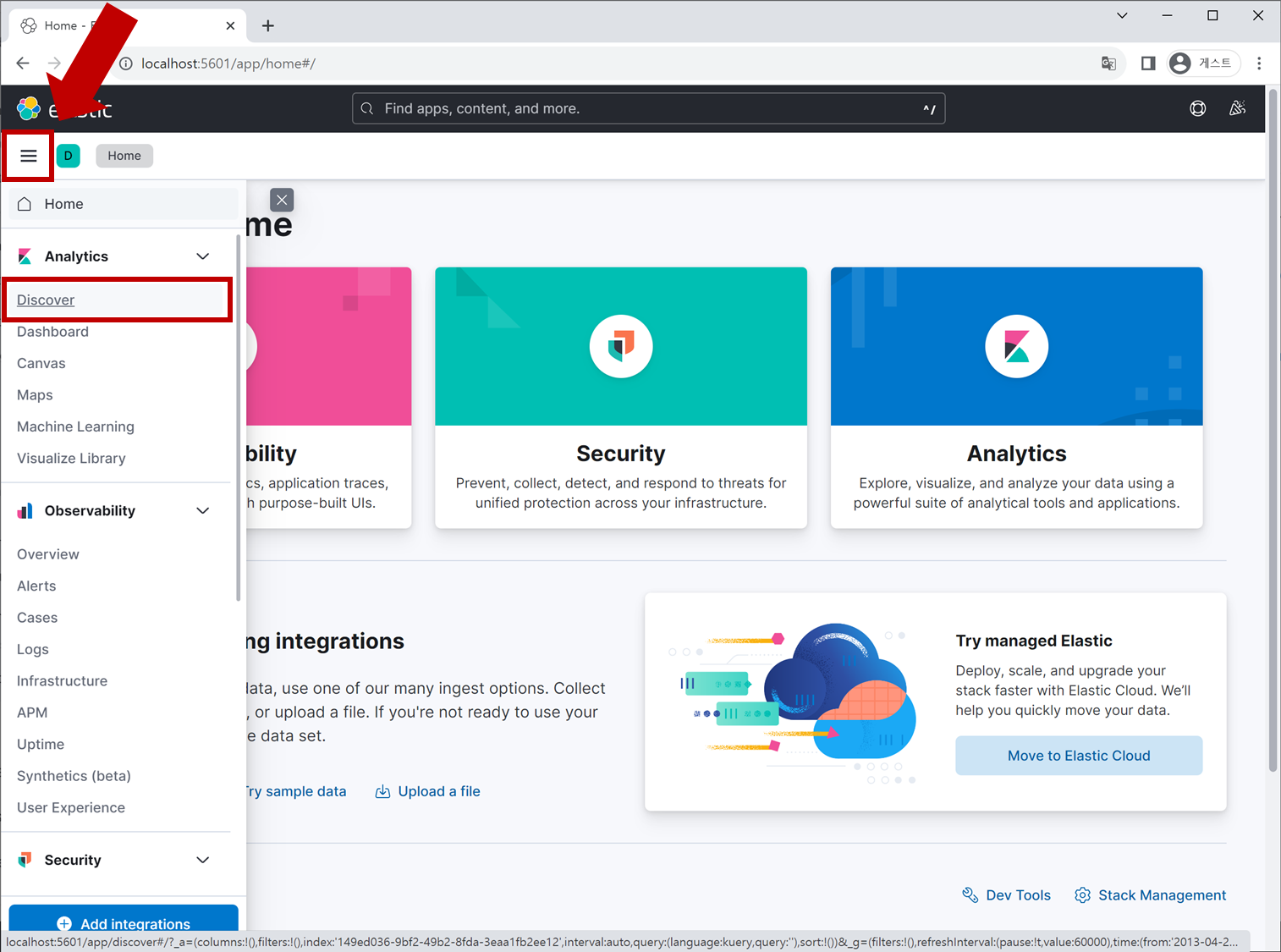
Create data view라는 버튼을 찾아 클릭합니다.
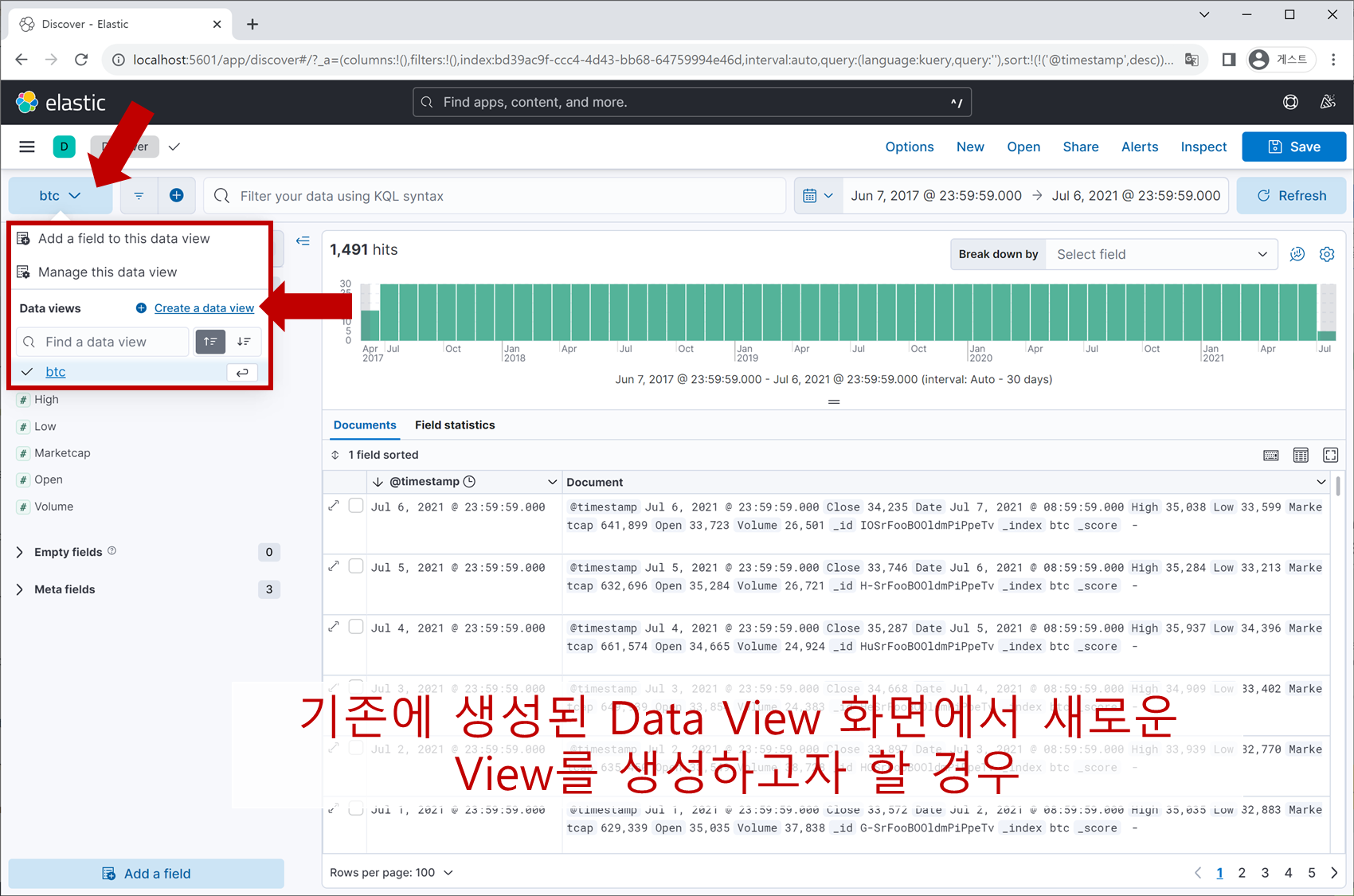
Data View Name과 Index 명을 입력합니다. Index 명은 trade.json 파일을 열어보면 아시겠지만 ‘btc2’로 지정이 되어 있습니다. 마지막으로 Timestamp field에 데이터 항목 중 하나인 Date를 지정해줍니다.
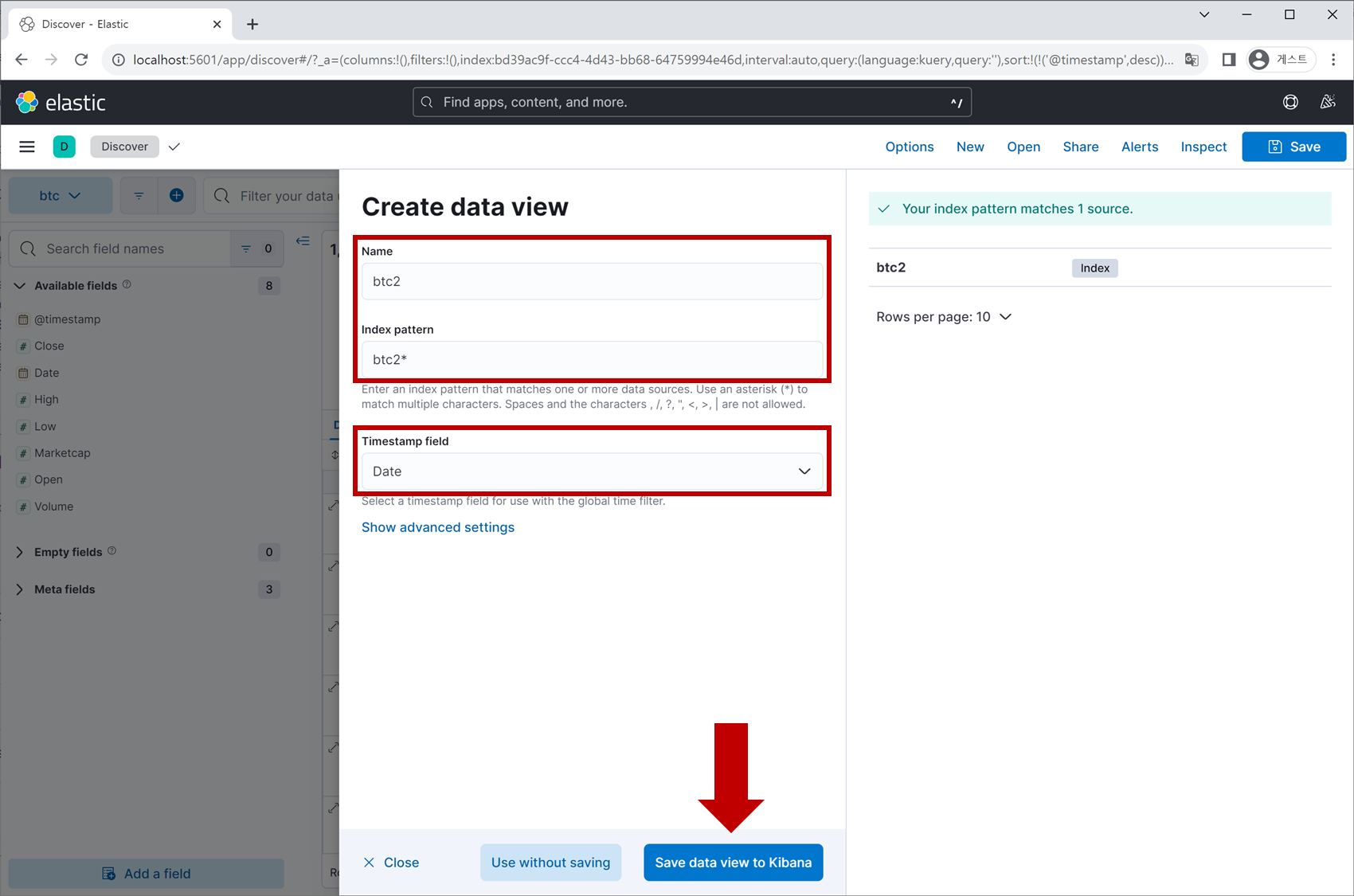
Save data view to Kibana 버튼을 누르면 끝입니다.
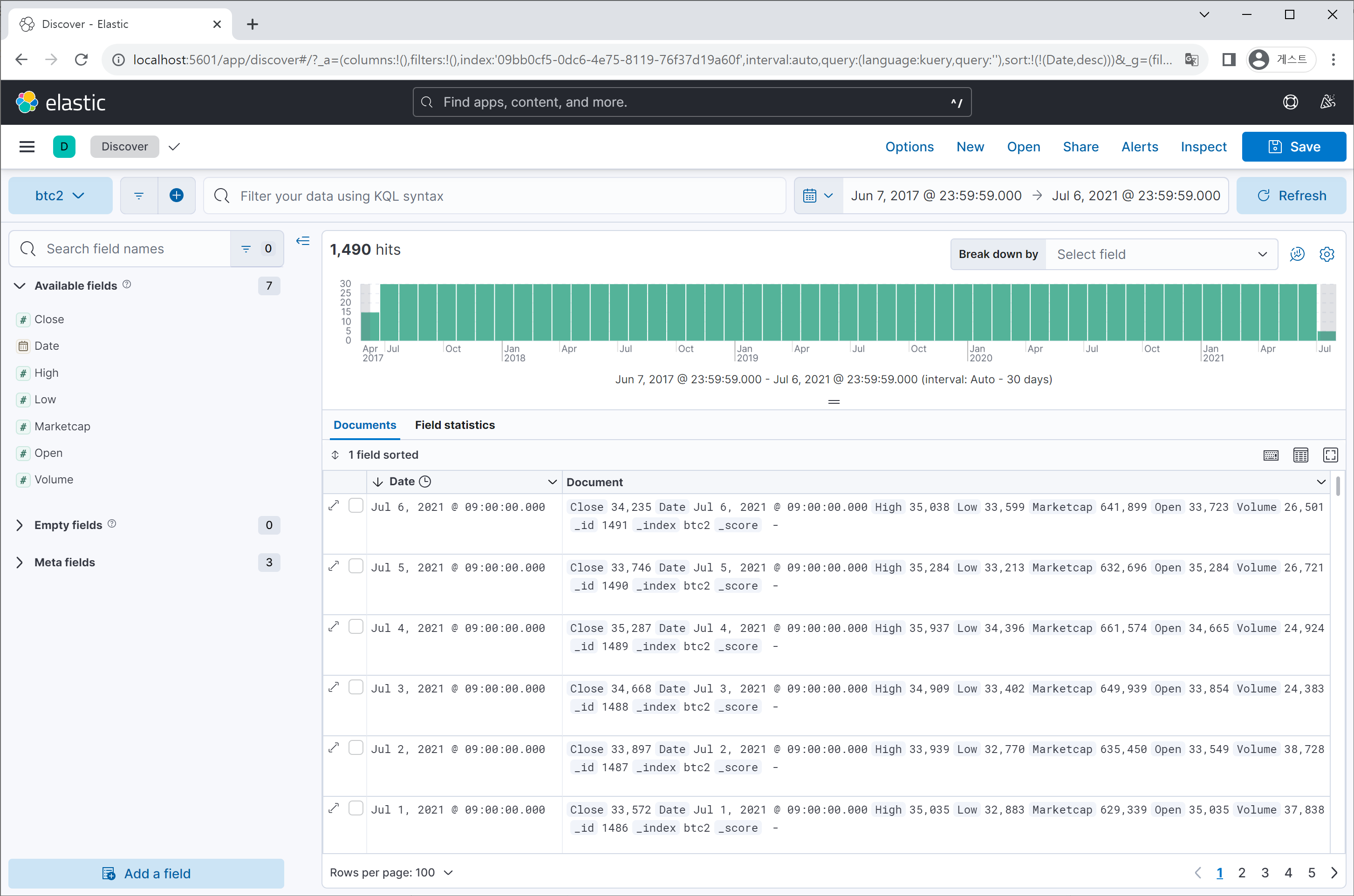
방식 C: Logstash로 파일 읽어서 데이터 업로드
방식 B는 데이터 포맷을 json으로 변환해야할 뿐만 아니라 Index 생성 따로, bulk 데이터 전송 따로 명령어로 직접 쳐줘야하니 그리 내키는 방법은 아닙니다.
방식 A 은 쉽고 간결하긴 하나 실시간, 그리고 대용량의 데이터를 수집하는 ELK 사용 목적을 고려하면 역시 적합한 방법이라 하기 어렵습니다. 앞의 2가지 방식은 튜토리얼용으로 소개를 드렸고, 이번에는 ELK를 구성하는 Elasticsearch, Logstash, Kibana를 모두 이용하는 방법입니다.
Logstash가 설치되어 있다는 가정 하에 (아닐 경우 https://citizen.tistory.com/58을 참고해주세요) conf 파일을 아래와 같이 작성하여 Logstash 서비스를 활성화시켜 봅니다.
# logstash-trade.conf
input {
file {
path => "/home/pyro/elk-exercises/trade.csv" # 'trade.csv' 파일이 있는 Path로 수정하세요
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
# csv 파일 읽기
csv {
separator => ","
columns => ["Date", "High", "Low", "Open", "Close", "Volume", "Marketcap"]
}
mutate {gsub => ["Date", " 23:59:59", '']} # 시/분/초 제거
}
output {
elasticsearch {
hosts => "localhost"
index => "btc3" # index 명은 중복되지 않게 'btc3'로 지정
}
}$ logstash -f ~/logstash-trade.conf
Logstash가 성공적으로 동작하였다면, Kibana 웹페이지로 돌아와 ‘btc3’라는 Index가 생성되었는지 확인해보고 Data view를 생성해봅니다.

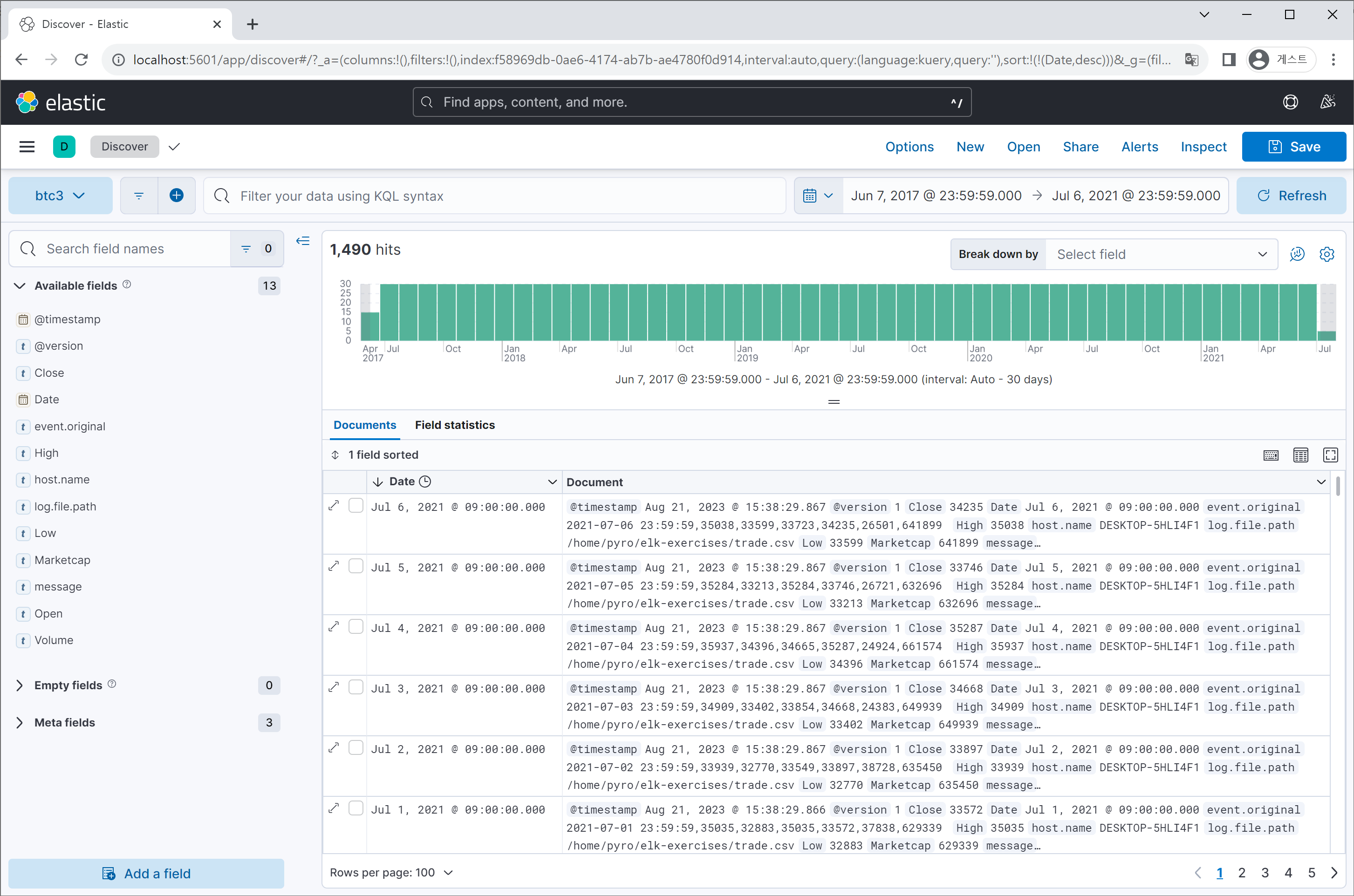
2. 데이터 분석
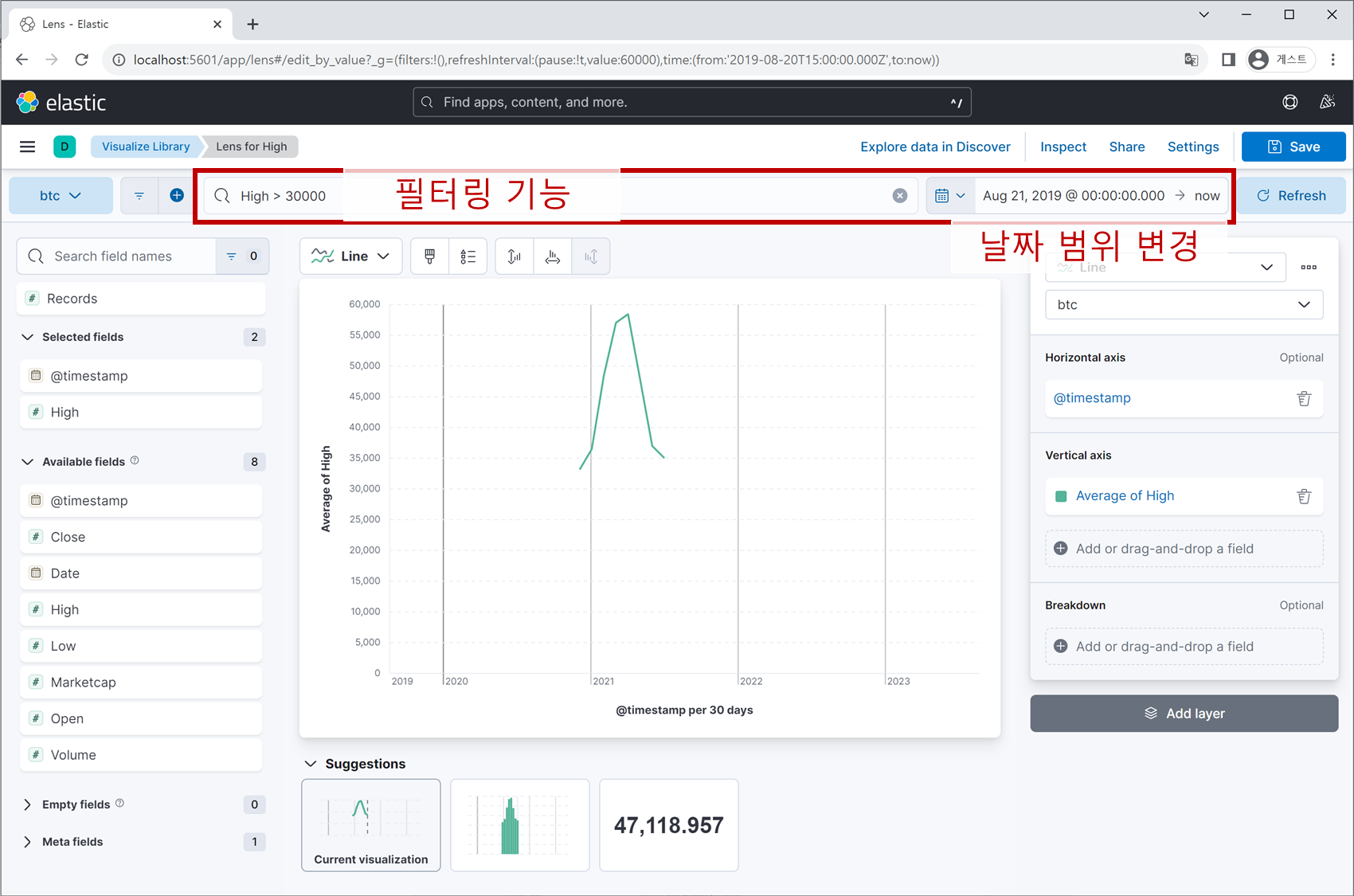
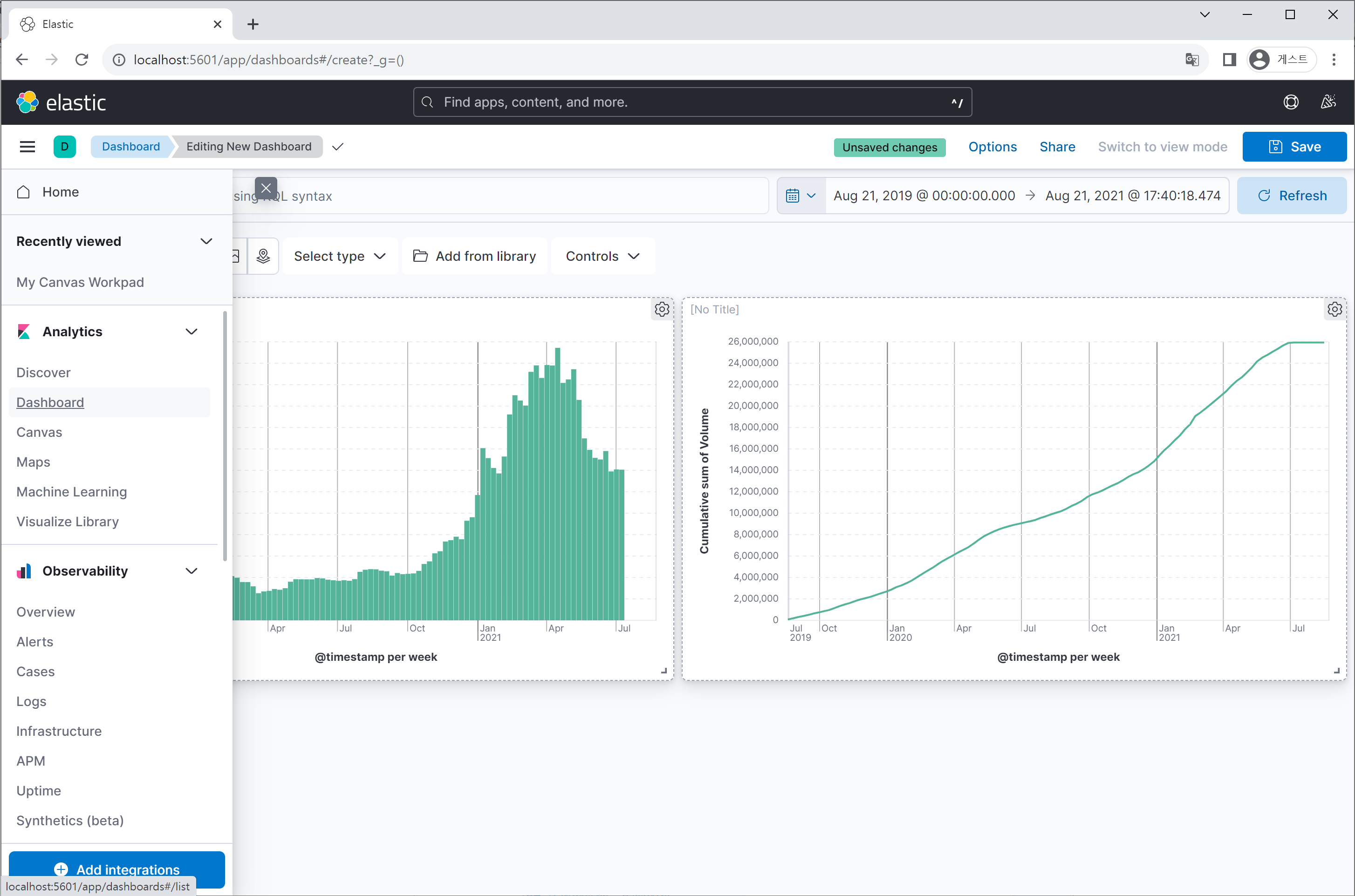
지금 보이는 화면은 ‘Discover’ 탭의 UI로 상단에는 필터링 기능과 데이터의 수집 시간대를 표시하는 영역이 존재하며, 좌측에는 데이터 field 리스트, 중앙에는 각 field별 통계치를 볼 수 있는 공간이 있습니다.
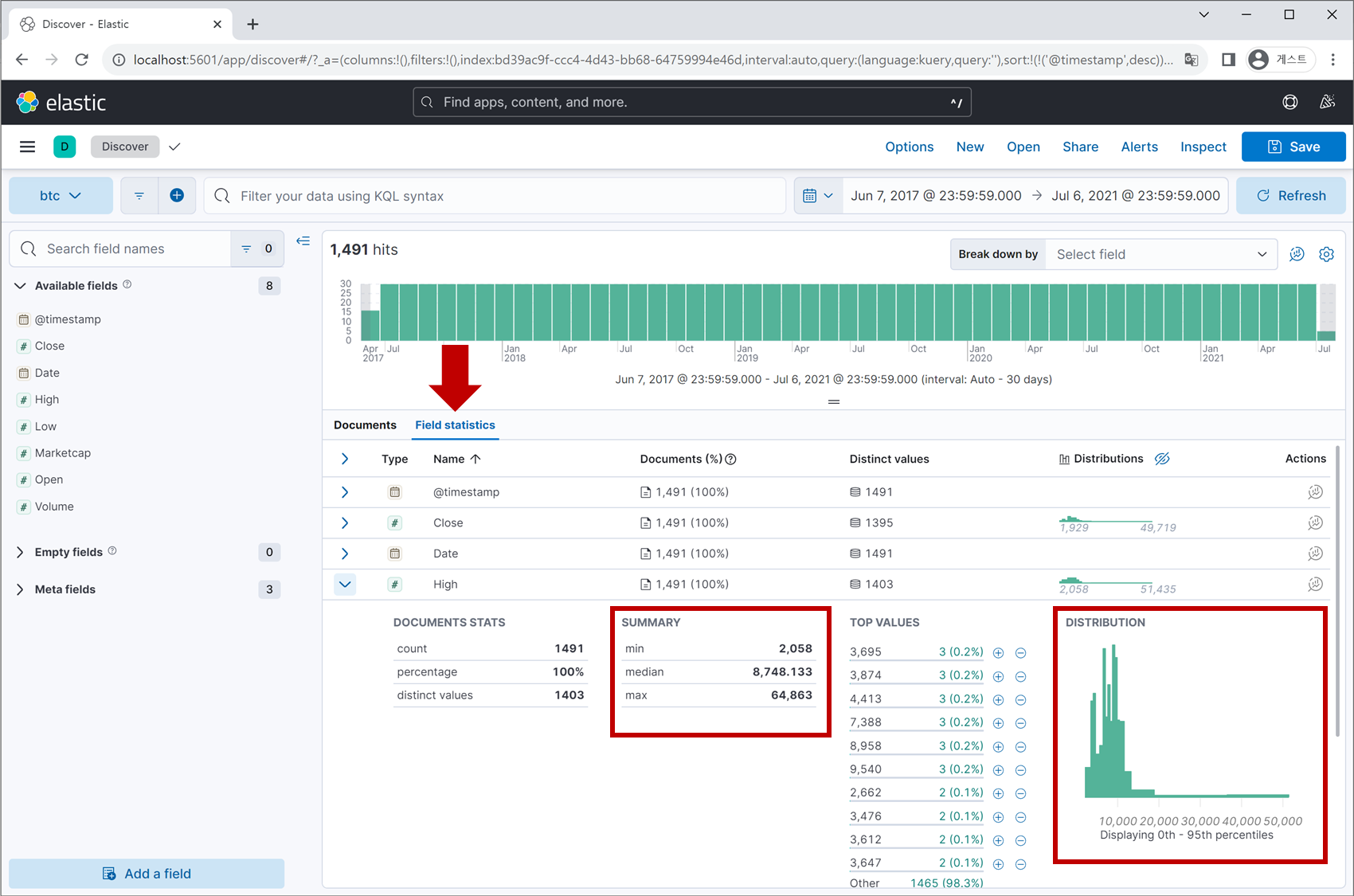
각 field 행의 우측 끝에 있는 아이콘을 클릭하면 정교한 차트를 시각화할 수 있으며,
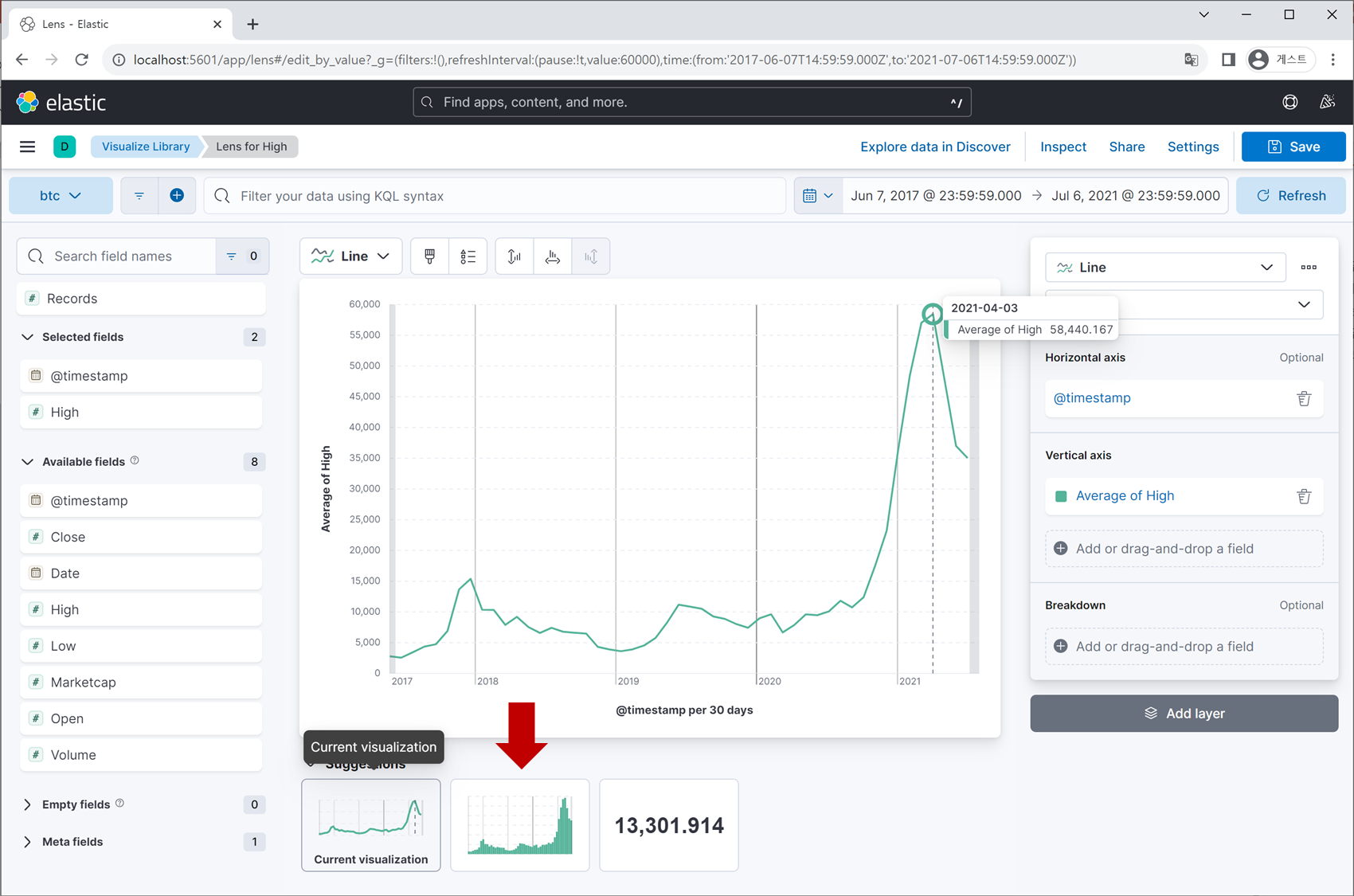
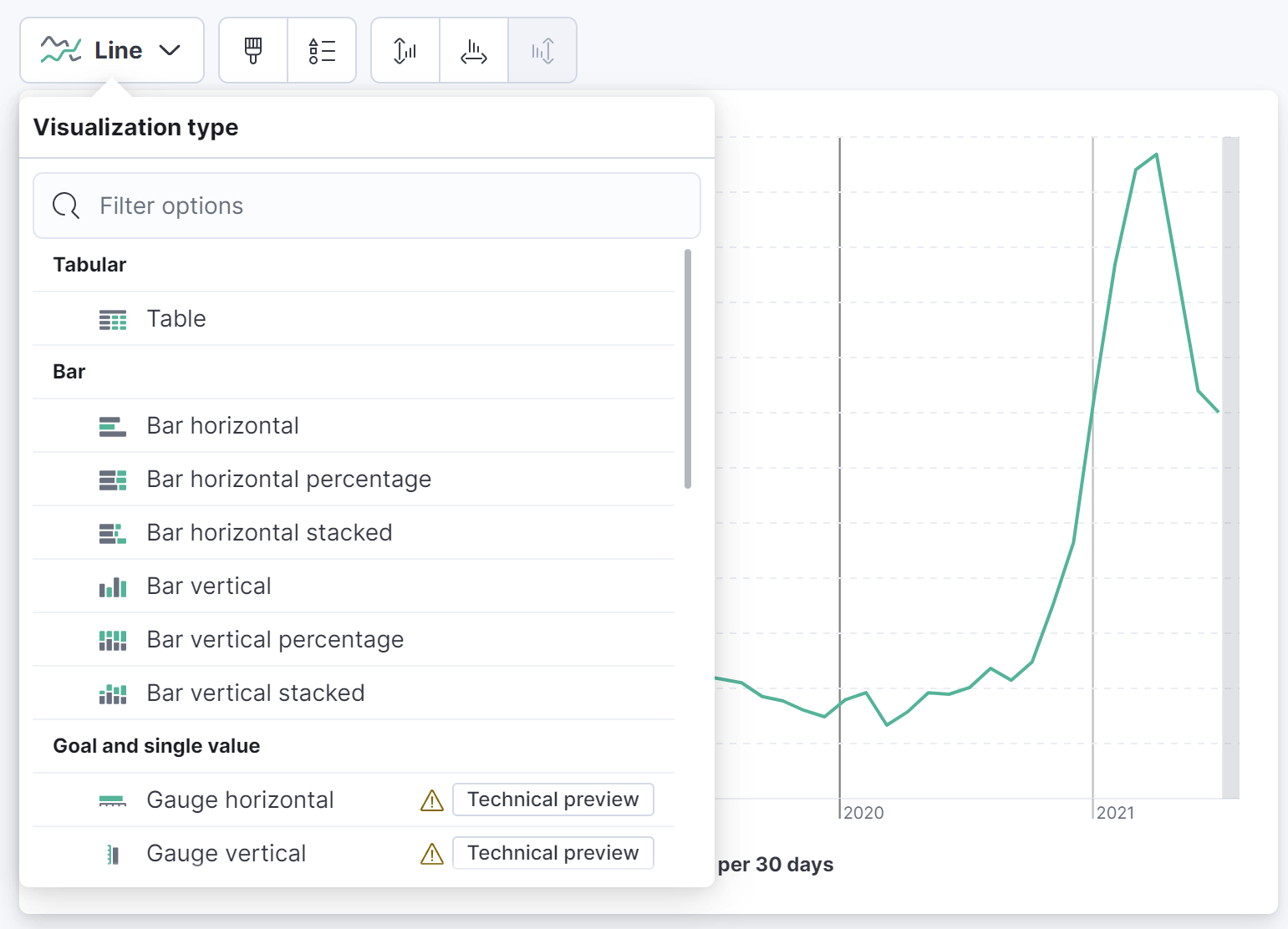
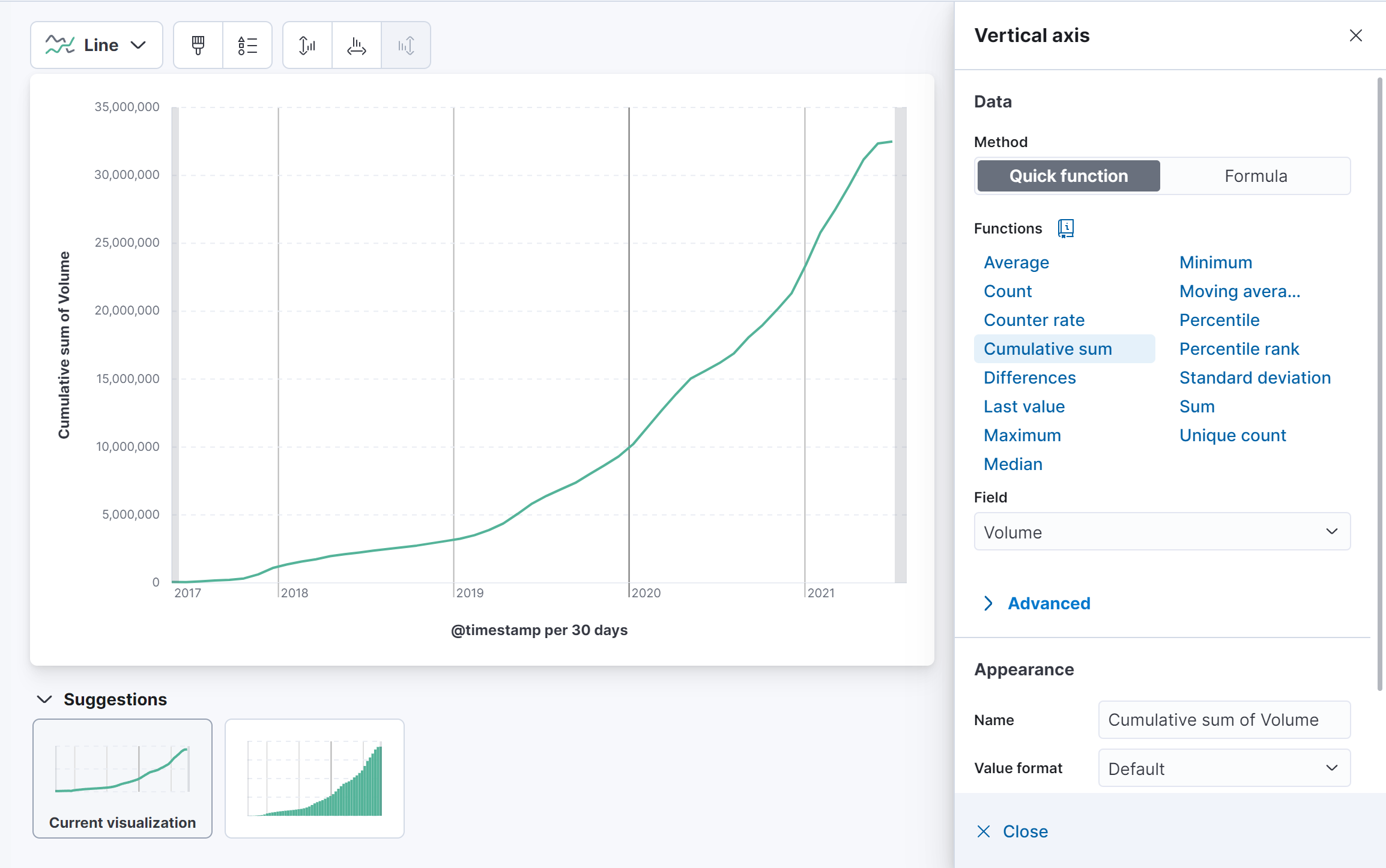
다양한 차트 형태, 분석하고자 하는 통계 값, 필터링 옵션 등을 지정할 수 있습니다.
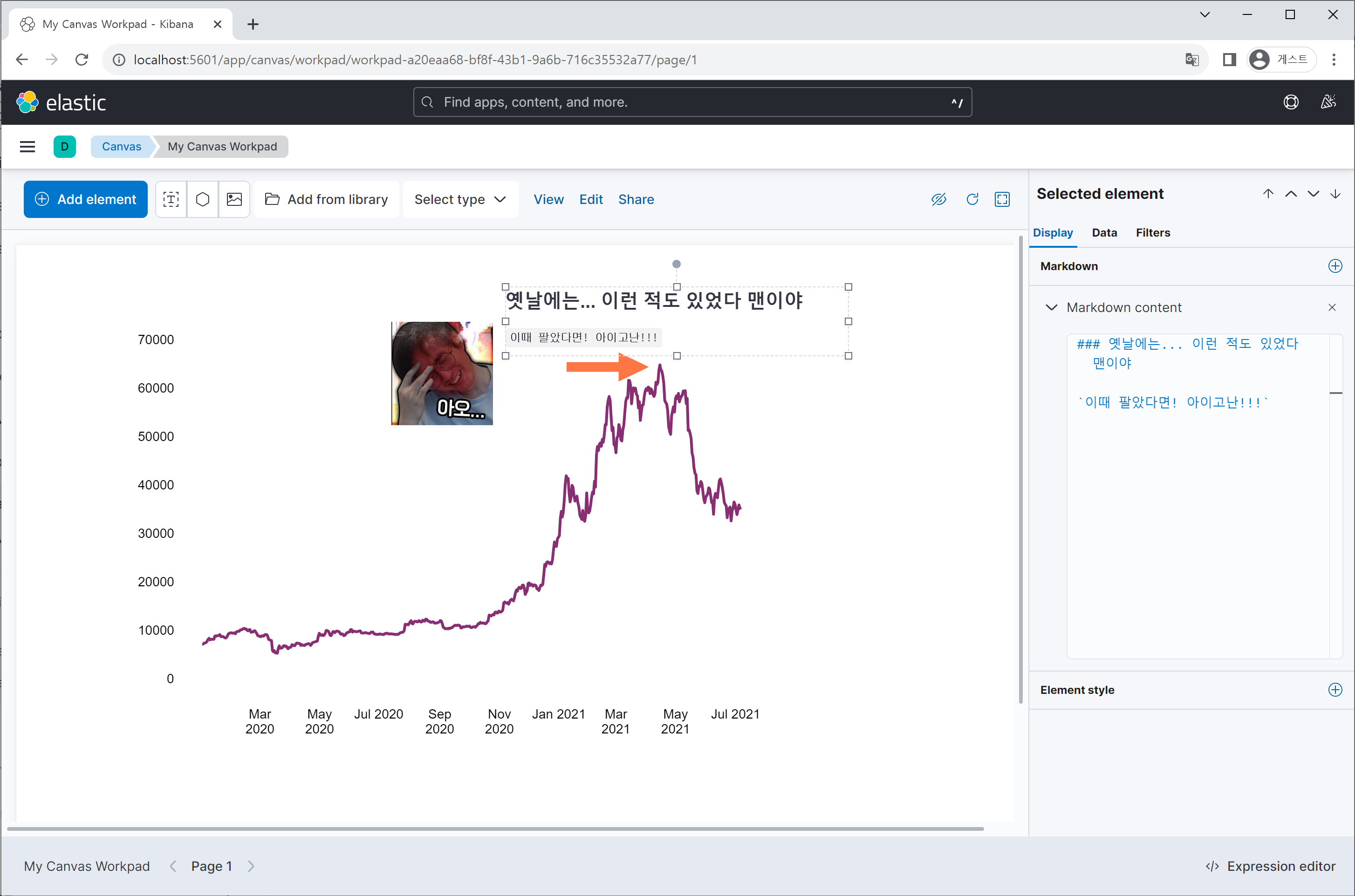
그 외에도 Dashboard라고 여러 차트를 한번에 시각화 할수 있는 도구(Grafana와 비슷하죠?)와 차트 위에 그림이나 글씨를 넣어 다이어그램을 만드는 Canvas와 같은 도구도 탑재되어 있습니다.
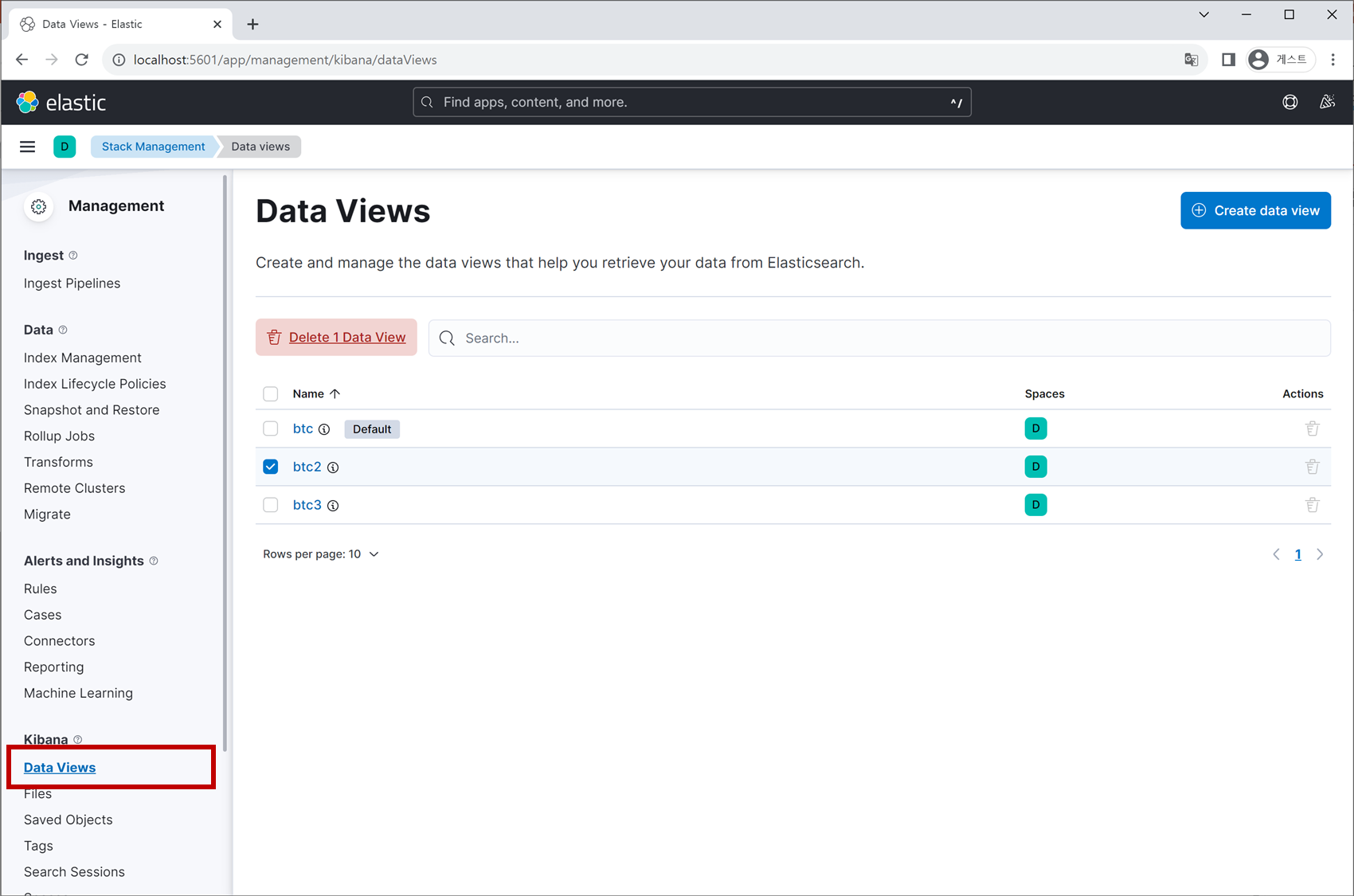
3. Data Index/View 설정
마지막으로 볼 것은 Kibana 인터페이스에서 Data Index와 Data View를 다루는 기능입니다. 도구 메뉴 버튼 **≡** 을 클릭하고 Management > Stack Management 탭을 선택합니다.
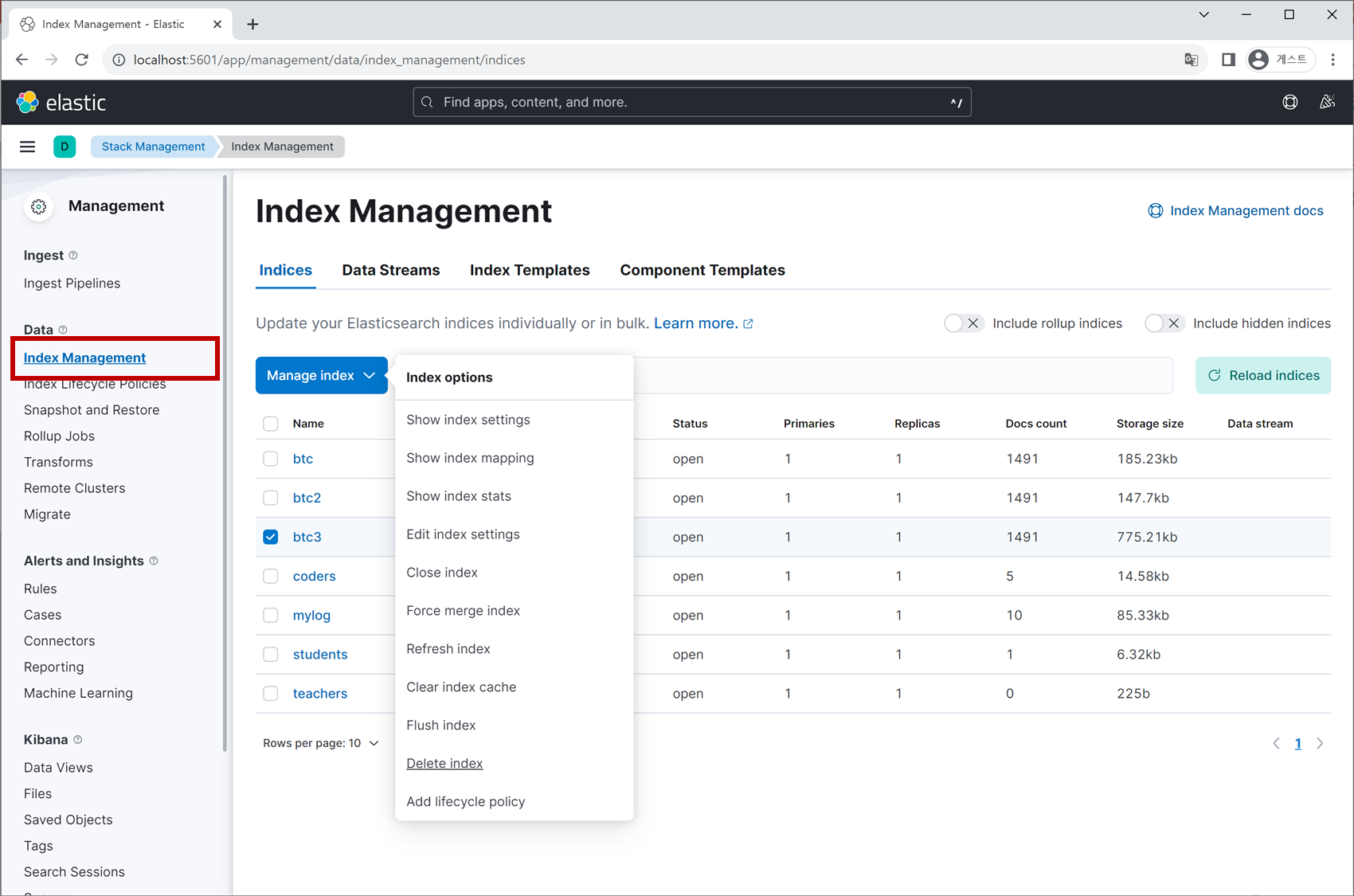
그러면 좌측에 있는 메뉴 항목들이 변하게 되는데요. 이 중에 Index Management 탭에 들어가서 Elasticsearch에 저장된 Index들의 리스트를 조회하고 삭제할 수 있습니다. 다만 개별 데이터(ELK에서는 ‘document’라고 하죠)를 생성/수정/삭제은 불가능합니다.
마찬가지로 ‘Data Views’ 탭을 클릭하면 앞서 생성하였던 데이터 분석 환경 각각에 대한 정보를 확인 가능합니다.