데이터 사이언스, 특히 Python에서 데이터를 담고 가공 및 분석하기 위한 자료구조로 pandas 패키지의 Dataframe을, 연산작업을 위한 자료구조로 numpy 패키지의 ndarray를 많이 사용합니다. 소스 데이터가 csv, json 또는 기타 다른 형태로 제공되든 간에, pandas는 이를 정형화된 테이블 구조로 변환하여 데이터 삽입, 수정, 필터링, 각 줄 또는 열에 대한 operation 등을 매우 손쉽게 처리해줍니다.
패키지 설치는 간단하니 길게 설명하지 않겠습니다.
$ pip install pandas1. 데이터 읽어오기
예제가 있어야 할 것 같아 Kaggle에서 활용할 수 있는 데이터셋을 링크로 걸어둡니다. 가볍게 pandas 함수 정도만 알아보실 분들은 건너뛰셔도 됩니다. 아래 주소에서 cars_24_combined.csv 파일을 받아 cars.csv로 이름 변경 후 본 포스트에서 쭉 이어 사용하였습니다.
https://www.kaggle.com/datasets/ujjwalwadhwa/cars24com-used-cars-dataset?select=cars_24_combined.csv
Cars24.com Used Cars dataset
Examine the effect on the price of a used car based on different features.
www.kaggle.com
CSV 파일 읽기
read_csv 함수로 파일을 읽어 df에 저장하고, df를 단독으로 print해보면 아래와 같은 테이블을 시각화할 수 있습니다.
import pandas as pd
df = pd.read_csv('cars.csv')
df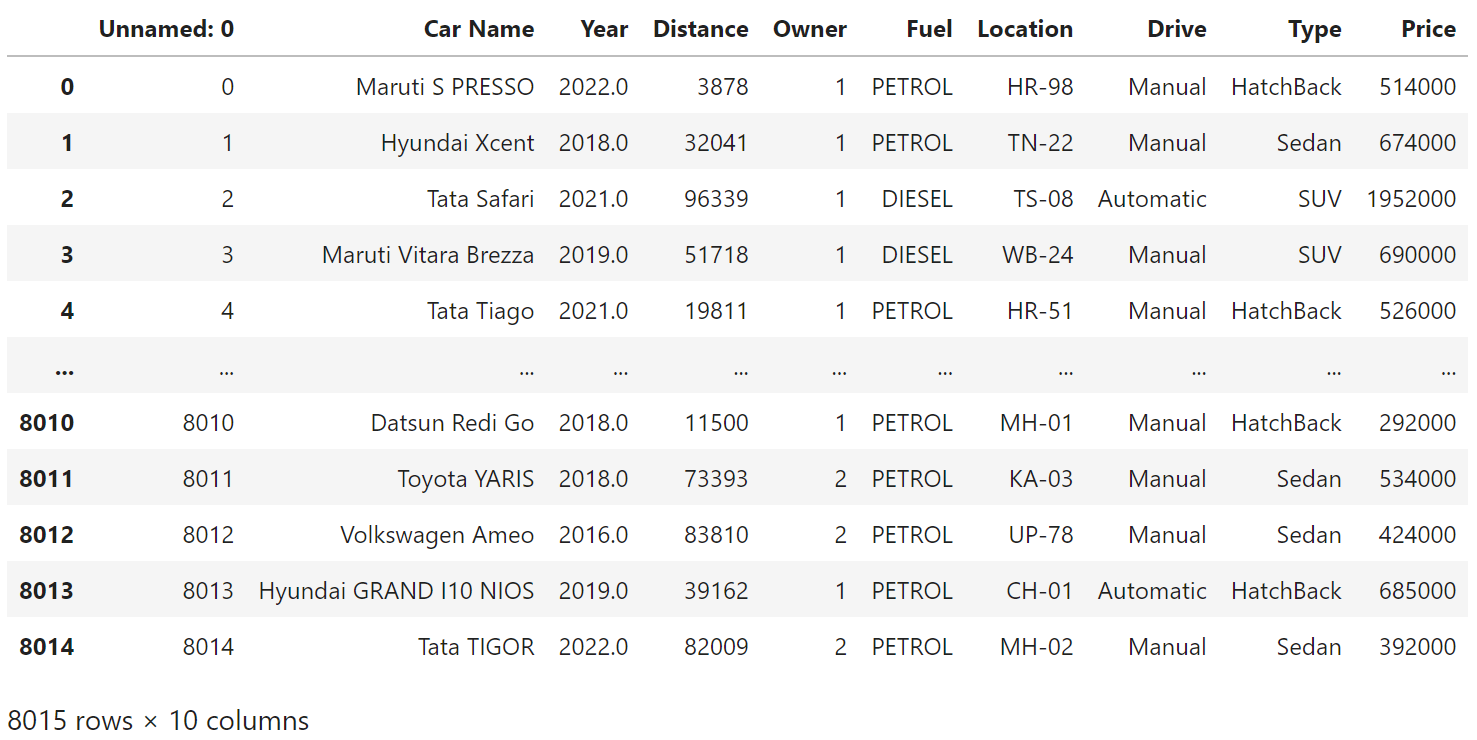
Excel 파일 읽기
표 작업할 때는 Excel(.xlsx)을 쓰긴한다지만, 대체로 저희가 사용하게 될 데이터들은 .csv 포맷의 데이터들입니다. xlsx 파일을 Python에서 읽으려면 xlrd 패키지를 하나 더 설치해야 하는데요, 여기에 버전에 따라 dependency 문제가 번거롭게 걸리기도 하니 어지간하면 xlsx 파일은 데이터로서 활용하지 않는다고 생각하는게 이롭습니다.
$ pip install xlrdimport pandas as pd
df = pd.read_excel('cars.xlsx')
df
JSON 파일 읽기
import pandas as pd
df = pd.read_json('cars.json')
List 또는 Dictionary 자료형 읽기
파이썬 인터페이스에서 직접 생성한 배열 또는 딕셔너리 자료형을 Dataframe으로 변환할 수 있습니다.
import pandas as pd
# list 읽기
list_data = [
['Maruti S PRESSO', 2022, 3878, 1, 'PETROL', 'HR-98', 'Manual', 'HatchBack', 514000],
['Hyyndai Xcent', 2018, 32041, 1, 'PETROL', 'TN-22', 'Manual', 'Sedan', 674000],
['Tata Safari', 2021, 96339, 1, 'DIESEL', 'TS-08', 'Automatic', 'SUV', 1952000]
]
df = pd.DataFrame(list_data, columns=['Car Name', 'Year', 'Distance', 'Owner', 'Fuel', 'Location', 'Drive', 'Type', 'Price'])
# dictionary 읽기
dict_data = {
'Car Name': ['Maruti S PRESSO', 'Hyyndai Xcent', 'Tata Safari'], # 1번째 열
'Year': [2022, 2018, 2021], # 2번째 열
'Distance': [3878, 32041, 96339], # 3번째 ...
'Owner': [1,1,1],
'Fuel': ['PETROL', 'PETROL', 'DIESEL'],
'Location': ['HR-98', 'TN-22', 'TS-08'],
'Drive': ['Manual', 'Manual', 'Automatic'],
'Type': ['HatchBack', 'Sedan', 'SUV'],
'Price': [514000, 674000, 1952000]
}
df = pd.DataFrame(dict_data)
2. 데이터 조회
행(row) 조회
리스트(List) 자료형과 같은 방법으로 인덱싱이 가능합니다.
import pandas as pd
df = pd.read_csv('cars.csv')
df[:10]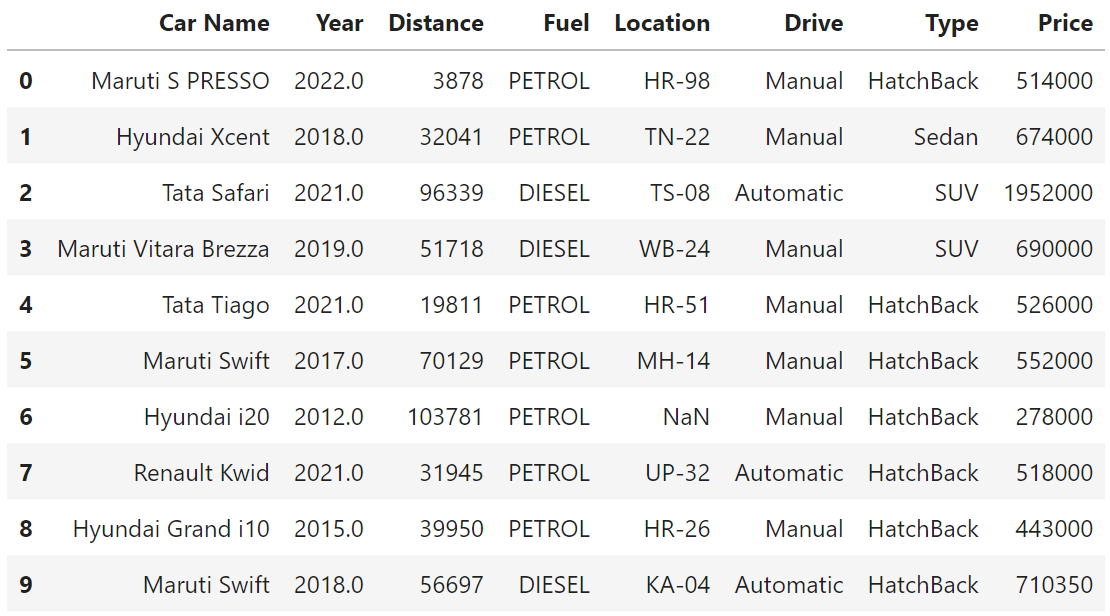
특정 열만 보여주기
df[['Car Name', 'Price']]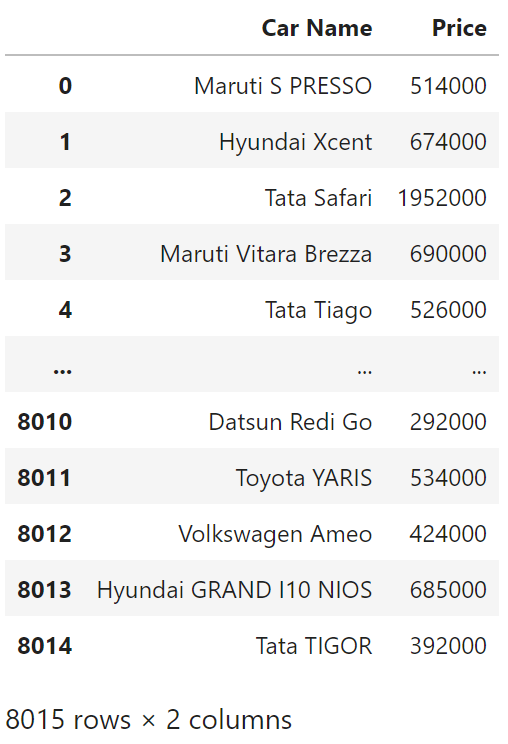
특정 행, 열로 구성된 블록 영역 조회
df.iloc[2:8, 2:5] # 2~7번째 행, 2~4번째 열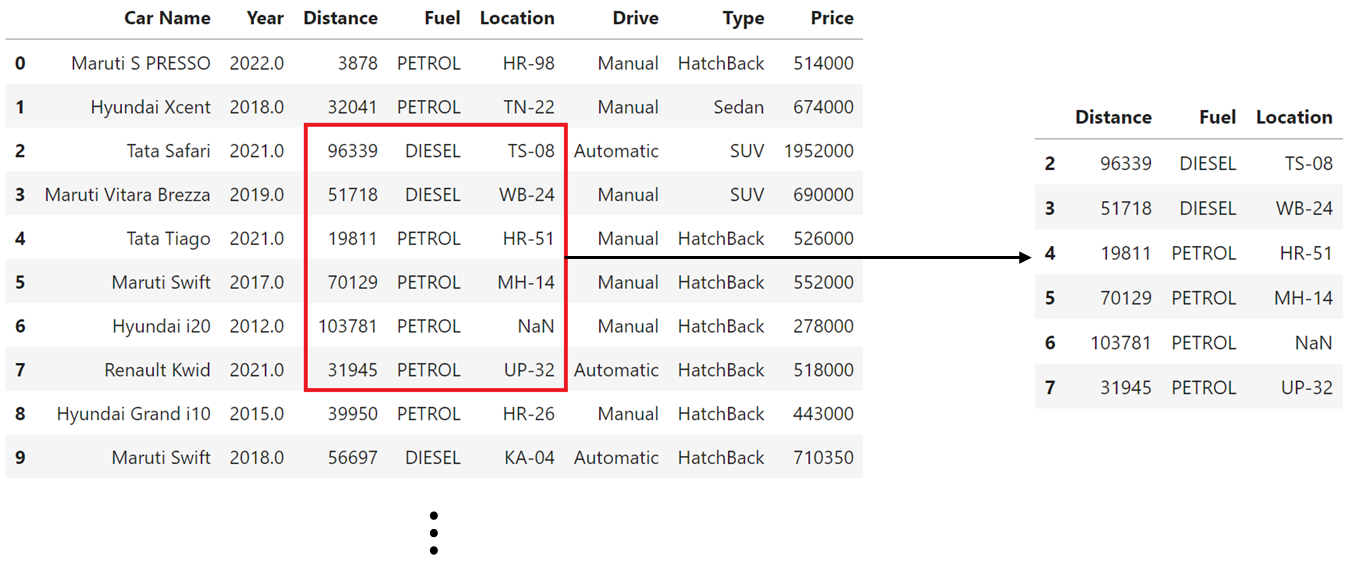
df.iloc[[2,4,5]] # 2,4,5번째 행 (행번호는 0번부터 시작합니다)
열에 해당하는 필드명을 직접 활용하여 조회하려면 iloc 대신 loc을 사용합니다.
df.loc[2:8, ['Car Name', 'Price']]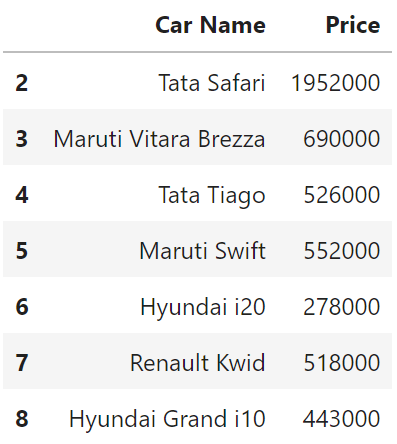
head()
상위 5개 샘플 데이터를 보여줍니다.
df.head()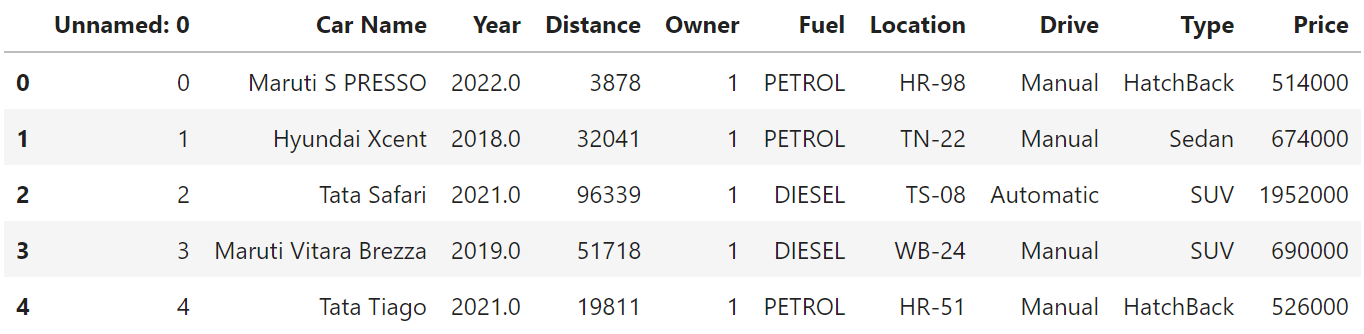
3. 필터링
boolean operation 식을 인덱스로 활용하여 전체 데이터셋에서 기준에 부합하는 샘플들을 추려낼 수 있습니다.
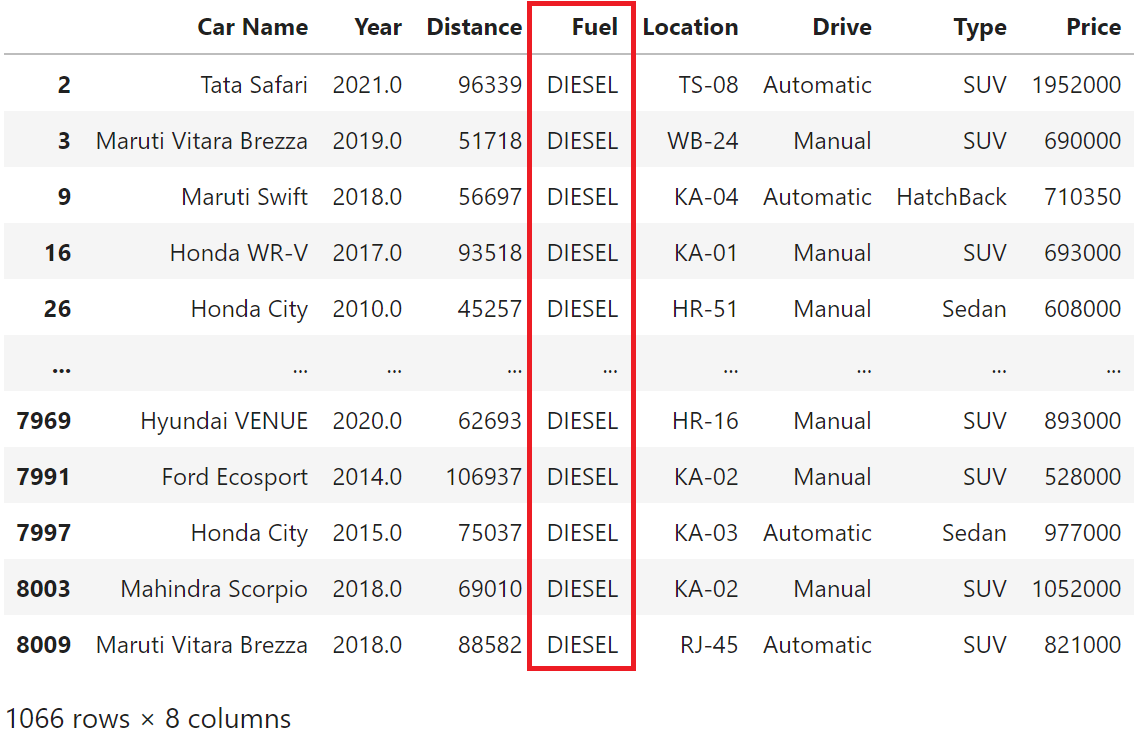
print(df['Fuel'] == 'DIESEL')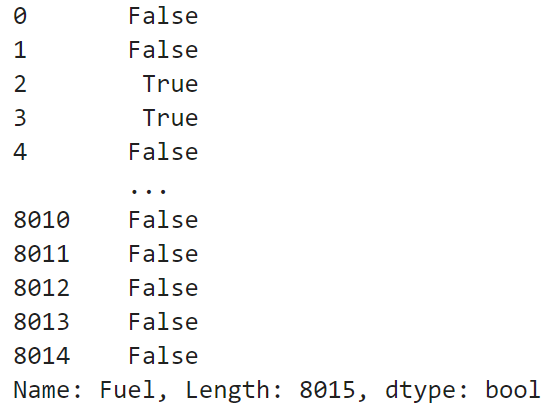
mask = (df['Fuel'] == 'DIESEL')
df[mask]